डेटा मॉडलिंग
{kind=link}
सॉफ्टवेयर इंजीनियरिंग में डेटा मॉडलिंग तकनीकों का प्रयोग करके औपचारिक डेटा मॉडल विवरणों को लागू करते हुए एक डेटा मॉडल का निर्माण करने की प्रक्रिया डेटा मॉडलिंग कहलाती है।
अवलोकन
डेटा मॉडलिंग एक विधि है, जिसका प्रयोग किसी संगठन की व्यापारिक प्रक्रियाओं का समर्थन करने के लिये आवश्यक डेटा आवश्यकताओं को परिभाषित करने और उनका विश्लेषण करने के लिये किया जाता है। डेटा आवश्यकताओं को एक वैचारिक डेटा मॉडल से जुड़ी डेटा परिभाषाओं के रूप में रिकॉर्ड किया जाता है। वैचारिक मॉडल के वास्तविक क्रियान्वयन को तार्किक डेटा मॉडल कहा जाता है। एक वैचारिक डेटा मॉडल के क्रियान्वयन के लिये अनेक तार्किक डेटा मॉडलों की आवश्यकता हो सकती है। डेटा मॉडलिंग न केवल डेटा के तत्वों, बल्कि उनकी संरचनाओं और उनके बीच संबंधों को भी परिभाषित करती है।[2] डेटा मॉडलिंग तकनीकों और कार्यविधियों का प्रयोग एक मानक, स्थिर, आकलनीय रूप में डाटा को चित्रित करने के लिये किया जाता है, ताकि एक संसाधन के रूप में इसका प्रबंधन किया जा सके. उन सभी परियोजनाओं के लिये डेटा मॉडलिंग मानकों के प्रयोग की दृढ़तापूर्वक अनुशंसा की गई है, जिनमें किसी संगठन के आंतरिक डेटा को परिभाषित एवं विश्लेषित करने के लिये एक मानक साधन की आवश्यकता हो, उदा. डेटा मॉडलिंग का प्रयोग निम्नलिखित कार्यों के लिये किया जा सकता है:
- एक संसाधन के रूप में डेटा का प्रबंधन करने के लिये;
- सूचना प्रणालियों के एकीकरण के लिए;
- डेटाबेस/डेटा वेयरहाउस (जिन्हें डेटा रिपॉज़िटरी के नाम से भी जाना जाता है) के निर्माण के लिये
डेटा मॉडलिंग विभिन्न प्रकार की परियोजनाओं में और परियोजनाओं के अनेक चरणों में की जा सकती है। डेटा मॉडल प्रगतिशील होते हैं; किसी भी व्यापार या अनुप्रयोग के लिये कोई भी डेटा मॉडल कभी अंतिम नहीं होता. इसकी बजाय एक डेटा मॉडल को एक जीवित दस्तावेज माना जाना चाहिये, जो बदलते हुए व्यापार की प्रतिक्रिया के रूप में बदलेगा. आदर्श रूप से, डेटा मॉडल को एक रिपॉज़िटरी में रखा जाना चाहिये, ताकि समय के साथ इसे पुनः प्राप्त किया जा सके, विस्तारित किया जा सके और संपादित किया जा सके. व्हिटन (2004) ने डेटा मॉडलिंग के दो प्रकार निर्धारित किये:[3]
- रणनीतिक डेटा मॉडलिंग: यह एक सूचना प्रणाली रणनीति के निर्माण का भाग होती है, जो सूचना प्रणाली के संपूर्ण दृष्टिकोण और संरचना को परिभाषित करती है। सूचना इंजीनियरिंग एक कार्य-पद्धति है, जो इस विधि का प्रयोग करती है।
- सिस्टम विश्लेषण के दौरान डेटा मॉडलिंग: सिस्टम विश्लेषण में, नये डेटाबेसों के एक भाग के रूप में तार्किक डेटा मॉडलों का निर्माण किया जाता है।
डेटा मॉडलिंग किसी डेटाबेस के लिये व्यापारिक आवश्यकताओं के वर्णन के लिये भी एक तकनीक है। कभी-कभी इसे डेटाबेस मॉडलिंग कहा जाता है क्योंकि एक डेटा मॉडल को अंततः एक डेटाबेस में क्रियान्वित किया जाता है।[3]
डेटा मॉडलिंग के विषय
डेटा मॉडल
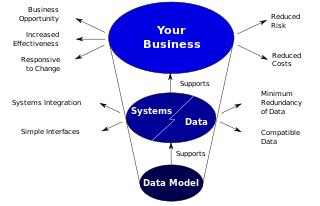
डेटा मॉडल डेटा की परिभाषा और उसका प्रारूप प्रदान करके डेटा और कम्प्यूटर तंत्रों का समर्थन करते हैं। यदि प्रणालियों के बीच ऐसा लगातार किया जाये, तो डेटा की संगतता प्राप्त की जा सकती है। यदि डेटा के भण्डारण और अभिगमन के लिये समान डेटा संरचनाओं का प्रयोग किया जाये, तो विभिन्न अनुप्रयोग डेटा को साझा कर सकते हैं। इसके परिणाम ऊपर सूचित किये गये हैं। हालांकि, प्रणालियों और इन्टरफेसों को बनाने, चलाने और इनका रख-रखाव करने की लागत, जितनी होनी चाहिये, अक्सर उससे अधिक होती है। वे व्यापार का समर्थन करने की बजाय उसमें बाधा भी उत्पन्न कर सकते हैं। एक मुख्य कारण यह है कि प्रणालियों और इंटरफेसों में लागू किये गये डेटा मॉडलों की गुणवत्ता कम होती है।[1]
- किसी विशिष्ट स्थान पर कार्यों को किये जाने के तरीकों के प्रति विशिष्ट व्यापारिक नियम अक्सर एक डेटा मॉडल की संरचना में स्थिर होते हैं। इसका अर्थ यह है कि व्यापारिक कार्यों को करने की विधि में छोटे परिवर्तनों के कारण कम्प्यूटर प्रणालियों और इंटरफेसों में बड़े परिवर्तन करने की आवश्यकता होती है।
- अक्सर इकाई प्रकारों की पहचान नहीं की जाती या गलत ढंग से की जाती है। इसका परिणाम डेटा, डेटा संरचना और कार्यात्मकता के दोहराव और साथ ही विकास और रख-रखाव में इस दोहराव की उपस्थिति की लागत के रूप में मिल सकता है।
- विभिन्न प्रणालियों के लिये डेटा मॉडल बहुत अधिक भिन्न होते हैं। इसका परिणाम यह होता है कि डेटा को साझा करने वाली प्रणालियों के बीच जटिल इंटरफेसों की आवश्यकता होती है। इन इंटरफेसों की लागत वर्तमान प्रणाली की लागत के 25-70% के बीच हो सकती है।
- ग्राहकों और आपूर्तिकर्ताओं के बीच डेटा इलेक्ट्रॉनिक रूप से साझा नहीं किया जा सकता क्योंकि डेटा की संरचना और अर्थ मानकीकृत नहीं किये गये हैं। उदाहरण के लिये, किसी प्रक्रिया संयंत्र के लिये इंजीनियरिंग डिज़ाइन डेटा और रेखाचित्रों का अंतरण अभी भी कभी-कभी कागज़ पर किया जाता है।
इन समस्याओं का कारण एक ऐसे मानक का अभाव है, जो यह सुनिश्चित करेगा कि डेटा मॉडल व्यापारिक आवश्यकताओं की पूर्ति भी करेंगे और संगत भी होंगे.[1]
वैचारिक, तार्किक और भौतिक योजनाएं
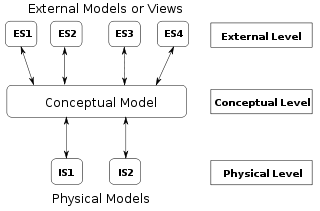
1975 में ANSI के अनुसार डेटा मॉडल का एक दृष्टान्त (Instance) तीन में से किसी एक प्रकार का हो सकता है:[4]
- वैचारिक स्कीमा: एक डोमेन के अर्थ-विज्ञान का वर्णन करता है, जो मॉडल का दायरा होता है। उदाहरण के लिये यह किसी संगठन या उद्योग की रुचि के क्षेत्र का मॉडल हो सकता है। यह उस डोमेन में महत्वपूर्ण वस्तुओं के प्रकारों का प्रतिनिधित्व करनेवाली एन्टिटी क्लासेस और एन्टिटी क्लासेस के जोड़ों के बीच संबंधों के बारे में संबंध निश्चयों से मिलकर बनता है। एक वैचारिक स्कीमा उन तथ्यों या प्रस्तावों के प्रकारों को वर्णित करता है, जिन्हें उस मॉडल का प्रयोग करके व्यक्त किया जा सकता हो. इस अर्थ में, यह स्वीकार्य अभिव्यक्तियों को एक कृत्रिम 'भाषा' में परिभाषित करता है, जिसका दायरा मॉडल के दायरे के द्वारा सीमित होता है।
- तार्किक स्कीमा: किसी विशिष्ट डेटा परिवर्तन तकनीक द्वारा प्रदर्शित अर्थ-विज्ञान का वर्णन करता है। इसमें अन्य वस्तुओं के अलावा तालिकाओं और स्तंभों, ऑब्जेक्ट उन्मुख क्लासेस और XML टैग्स का वर्णन शामिल होता है।
- भौतिक स्कीमा: उन भौतिक माध्यमों का वर्णन करता है, जिनके द्वारा डेटा का भण्डारण किया जाता है। यह विभाजनों, CPUs, टेबलस्पेस और इसी प्रकार की अन्य बातों से संबंधित होता है।
ANSI के अनुसार इस विधि का महत्व यह है कि यह तीन दृष्टिकोणों को एक दूसरे से सापेक्ष रूप से स्वतंत्र रहने की अनुमति देती है। तार्किक या वैचारिक मॉडल को प्रभावित किये बिना भण्डारण प्रौद्योगिकी को बदला जा सकता है। तालिका/स्तंभ संरचना वैचारिक मॉडल को (आवश्यक रूप से) प्रभावित किये बिना बदल सकती है। स्वाभाविक रूप से, प्रत्येक स्थिति में, संरचनाएं अन्य मॉडलों के साथ संगत बनी रहनी चाहिये. तालिका/स्तंभ संरचना इकाई क्लासेस और विशेषताओं के प्रत्यक्ष अनुवाद से भिन्न हो सकती है, लेकिन अंततः इसे अनिवार्य रूप से वैचारिक इकाई क्लास संरचना के उद्देश्यों की पूर्ति करनी चाहिये. अनेक सॉफ्टवेयर विकास परियोजनाओं के प्रारंभिक चरण एक वैचारिक डेटा मॉडल के निर्माण पर बल देते हैं। इस प्रकार के एक डिज़ाइन को एक तार्किक डेटा मॉडल में वर्णित किया जा सकता है। बाद वाले चरणों में, इस मॉडल को भौतिक डेटा मॉडल में रूपांतरित किया जा सकता है। हालांकि एक वैचारिक डेटा मॉडल को सीधे ही लागू कर पाना भी संभव है।
डेटा मॉडलिंग प्रक्रिया

व्यापारिक प्रक्रिया के एकीकरण के संदर्भ में, चित्र देखें, डेटा मॉडलिंग का परिणाम डेटाबेस के एकीकरण के रूप में मिलेगा. यह व्यापार प्रक्रिया मॉडलिंग का पूरक है, जिसका परिणाम अनुप्रयोग प्रोग्राम होता है, जो इस व्यापार प्रक्रिया का समर्थन करती है।[5]
वास्तविक डेटाबेस डिज़ाइन, डेटाबेस के एक विस्तृत डेटा मॉडल का निर्माण करने की प्रक्रिया है। इस तार्किक डेटा मॉडल में डिज़ाइन को एक डेटा परिभाषा भाषा में निर्मित करने के लिये आवश्यक सभी तार्किक और भौतिक डिज़ाइन चयन और भौतिक भण्डारण मापदण्ड होते हैं, जिनका प्रयोग तब एक डेटाबेस के निर्माण के लिये किया जा सकता है। सभी विशेषताओं से युक्त एक डेटा मॉडल में प्रत्येक इकाई के लिये विस्तृत विशेषताएं होती हैं। डेटाबेस डिज़ाइन शब्दावली का प्रयोग एक सकल डेटाबेस प्रणाली के डिज़ाइन के विभिन्न भागों का वर्णन करने के लिये किया जा सकता है। मुख्यतः और सर्वाधिक सही रूप में, इसे डेटा के भण्डारण के लिये प्रयुक्त मूल डेटा संरचनाओं की एक तार्किक रचना के रूप में समझा जा सकता है। एक संबंधपरक मॉडल में ये तालिकाएं और व्यू होते हैं। एक ऑब्जेक्ट डेटाबेस में इकाइयां और संबंध सीधे ऑब्जेक्ट क्लासेस और नामित संबंधों से जुड़े होते हैं। हालांकि, डेटाबेस डिज़ाइन शब्दावली का प्रयोग डिज़ाइनिंग की सकल प्रक्रिया, न केवल मूल डेटा संरचनाओं, बल्कि एक डेटाबेस प्रबंधन तंत्र या DBMS में एक सकल डेटाबेस अनुप्रयोग के भाग के रूप में प्रयुक्त फॉर्म्स और क़्वेरीज़ भी, को लागू करने के लिये भी किया जा सकता है।
इस प्रक्रिया में सिस्टम इंटरफेस पर वर्तमान सिस्टम के विकास और समर्थन लागत का 25% से 70% तक खर्च आता है। इस लागत का मुख्य कारण यह है कि ये सिस्टम एक सामान्य डेटा मॉडल का प्रयोग नहीं करते. यदि डेटा मॉडलों को एक प्रणाली-दर-प्रणाली आधार पर विकसित किया जाए, तो आच्छादित क्षेत्रों में न केवल समान विश्लेषण दोहराया जाता है, बल्कि उनके बीच इंटरफेस का निर्माण करने के लिये आगे और विश्लेषण करना भी अनिवार्य होता है। अधिकांश प्रणालियों में समान बुनियादी घटक होते हैं, जो किसी विशिष्ट उद्देश्य के लिये पुनः विकसित किये जाते हैं। उदाहरण के लिये, निम्नलिखित में समान बुनियादी वर्गीकरण मॉडल का प्रयोग एक घटक के रूप में किया जा सकता है:[1]
- सामान की सूची,
- उत्पाद और ब्रांड विनिर्देशन,
- उपकरण विनिर्देशन.
उन्हीं घटकों को पुनः विकसित किया जाता है क्योंकि हमारे पास यह बताने का कोई तरीका नहीं है कि वे समान हैं।
मॉडलिंग की कार्य-पद्धतियां
डेटा मॉडल रुचि के सूचना क्षेत्रों का प्रतिनिधित्व करते हैं। हालांकि, डेटा मॉडलों के निर्माण की अनेक विधियां हैं, लेकिन लेन सिल्वरस्टोन (1997) के अनुसार[6] इनमें से केवल दो विधियां ही श्रेष्ठ हैं, टॉप-डाउन और बॉटम-अप:
- बॉटम-अप मॉडल अक्सर री-इंजीनियरिंग प्रयास का एक परिणाम होते हैं। सामान्यतः वे पूर्व-निर्मित डेटा संरचना फॉर्म, अनुप्रयोग स्क्रीन पर स्थित क्षेत्रों या रिपोर्टों के साथ शुरु होते हैं। एक उद्यम के दृष्टिकोण से ये मॉडल सामान्यतः भौतिक, अनुप्रयोग-विशिष्ट और अपूर्ण होते हैं। यह संभव है कि वे डेटा साझेदारी को प्रचारित न करें, विशेषतः यदि वे संगठन के अन्य भागों के संदर्भ के बिना बनाये गये हों.[6]
- दूसरी ओर, टॉप-डाउन तार्किक डेटा मॉडल विषय-क्षेत्र के विशेषज्ञों से सूचना प्राप्त करके एक संक्षिप्त रूप में निर्मित किये जाते हैं। यह संभव है कि कोई सिस्टम एक तार्किक मॉडल में सभी इकाइयों की लागू न करता हो, लेकिन यह मॉडल एक संदर्भ बिंदु या टेम्पलेट के रूप में कार्य करता है।[6]
कभी-कभी मॉडल इन दोनों विधियों के मिश्रण के रूप में निर्मित किये जाते हैं: किसी अनुप्रयोग की संरचना और डेटा आवश्यकताओं और संरचना पर विचार करके और एक विषय-क्षेत्र मॉडल का सतत संदर्भ देते हुए. दुर्भाग्य से, अनेक वातावरणों में, एक तार्किक डेटा मॉडल और एक भौतिक डेटा मॉडल के बीच अंतर अस्पष्ट होता है। इसके अतिरिक्त, कुछ CASE उपकरण तार्किक और भौतिक डेटा मॉडलों के बीच अंतर नहीं करते.[6]
इकाई संबंध चित्र

डेटा मॉडलिंग की अनेक संकेत-पद्धतियां होती हैं। वास्तविक मॉडल को अक्सर "इकाई संबंध मॉडल (Entity relationship model)" कहा जाता है क्योंकि यह डेटा को इसमें वर्णित इकाइयों और उनके संबंधों के संदर्भ में चित्रित करता है।[3] एक इकाई-संबंध मॉडल (ERM) संरचनाबद्ध डेटा का एक संक्षिप्त वैचारिक प्रदर्शन होता है। इकाई-संबंध मॉडलिंग एक संबंधात्मक स्कीमा डेटाबेस मॉडलिंग विधि है, जिसका प्रयोग सॉफ्टवेयर इंजीनियरिंग में किसी सिस्टम, सामान्यतः एक संबंधात्मक डेटाबेस, के एक प्रकार के वैचारिक डेटा मॉडल (या अर्थ-विज्ञान डेटा मॉडल) का निर्माण करने के लिये किया जाता है और इसकी आवश्यकताएं एक टॉप-डाउन रूप में होती हैं।
इन मॉडलों का प्रयोग सूचना-तंत्रों के निर्माण के पहले चरण में आवश्यकता विश्लेषण के दौरान सूचना आवश्यकताओं या उस सूचना के प्रकार को बताने के लिये किया जाता है, जिसे किसी डेटाबेस में रखा जाना है। डेटा मॉडलिंग तकनीक का प्रयोग किसी विशिष्ट संवाद-विश्व, अर्थात् रुचि के क्षेत्र के लिये किसी भी तात्विकी का वर्णन (अर्थात प्रयुक्त शब्दावलियों और उनके संबंधों का परिचय और वर्गीकरण) करने के लिये किया जा सकता है।
डेटा मॉडलों के निर्माण के लिये अनेक तकनीकें विकसित की गईं हैं। हालांकि ये कार्य-पद्धतियां डेटा मॉडलरों को उनके कार्य में मार्गदर्शन करतीं हैं, लेकिन समान कार्य-पद्धति का प्रयोग करनेवाले दो भिन्न लोग अक्सर दो भिन्न परिणामों के साथ सामने आएंगे. सर्वाधिक उल्लेखनीय हैं:
- बैचमैन चित्र
- बार्कर संकेतन
- चेन
- डेटा वॉल्ट मॉडलिंग
- विस्तारित बैकस-नॉर प्रारूप
- IDEF1X
- ऑबजेक्ट-संबंधात्मक मानचित्रण
- ऑब्जेक्ट भूमिका मॉडलिंग
- संबंधात्मक मॉडल
सामान्य डेटा मॉडलिंग
सामान्य डेटा मॉडल पारंपरिक डेटा मॉडलों के सामान्यीकरण होते हैं। वे मानकीकृत सामान्य संबंध प्रकारों को और साथ ही वस्तुओं के उन प्रकारों को परिभाषित करते हैं, जो ऐसे संबंध-प्रकारों से जुड़ी हो सकती हैं। एक सामान्य डेटा मॉडल की परिभाषा एक प्राकृतिक भाषा की परिभाषा के समान ही होती है। उदाहरण के लिये, एक सामान्य डेटा मॉडल संबंधित वस्तुओं के प्रकारों से निरपेक्ष रहते हुए संबंधों के प्रकारों को एक 'वर्गीकरण संबंध', जो कि किसी एकल वस्तु और वस्तुओं के एक प्रकार (एक श्रेणी) के बीच एक द्विआधारी संबंध होता है और एक 'अंश-पूर्ण संबंध', जो कि दो वस्तुओं के बीच एक द्विआधारी संबंध होता है, जिनमें से एक वस्तु अंश की भूमिका में और दूसरी पूर्ण की भूमिका में होती है, के रूप में परिभाषित कर सकता है।
श्रेणियों की एक वितान्य सूची किसी एकल वस्तु का वर्गीकरण करने और किसी एकल वस्तु के लिये अंश-पूर्ण संबंध विनिर्देशित करने की अनुमति देती है। संबंधों के प्रकारों की एक वितान्य सूची के मानकीकरण के द्वारा, एक सामान्य डेटा मॉडल तथ्यों के प्रकारों की असीमित संख्या को व्यक्त कर पाने की क्षमता प्रदान करता है और यह प्राकृतिक भाषाओं की क्षमताओं का प्रयोग करेगा. दूसरी ओर, पारंपरिक डेटा मॉडलों का डोमेन दायरा निश्चित और सीमित होता है क्योंकि ऐसे मॉडलों की स्थापना (प्रयोग) केवल उस प्रकार के तथ्यों की व्याख्या करने की अनुमति देती है, जो मॉडल में पूर्व-परिभाषित हों.
अर्थ-विज्ञान डेटा मॉडलिंग
किसी DBMS की तार्किक डेटा संरचना, चाहे वह पदानुक्रमिक हो, नेटवर्क हो, या संबंधात्मक हो, डेटा की एक वैचारिक परिभाषा की आवाश्यकताओं की पूरी तरह पूर्ति नहीं कर सकती क्योंकि इसका दायरा सीमित होता है और यह उस DBMS द्वारा प्रयोग की गई क्रियान्वयन रणनीति की ओर झुकी हुई होती है।

अतः एक वैचारिक दृष्टिकोण से डेटा को परिभाषित करने की आवश्यकता के परिणामस्वरूप अर्थ-विज्ञान डेटा मॉडलिंग तकनीकों के विकास हुआ है। अर्थात्, डेटा के अर्थ को अन्य डेटा के साथ आपसी संबंधों के संदर्भ में परिभाषित करने की तकनीकें. जैसा कि चित्र में प्रदर्शित है, संसाधनों, विचारों, घटनाओं इत्यादि के संदर्भ में वास्तविक-विश्व को संकेत-रूप में भौतिक डेटा भण्डारों में परिभाषित किया जाता है। एक अर्थ-विज्ञान डेटा मॉडल एक संक्षेपण है, जो परिभाषित करता है कि ये चिन्ह वास्तविक-विश्व से किस प्रकार जुड़े हुए हैं। इस प्रकार अनिवार्य रूप से यह मॉडल वास्तविक-विश्व का एक सत्य प्रदर्शन होना चाहिये.[7]
एक अर्थ-विज्ञान डेटा मॉडल का प्रयोग अनेक उद्देश्यों के लिये किया जा सकता है, जैसे:[7]
- डेटा संसाधनों का नियोजन
- साझा करने योग्य डेटाबेस का निर्माण
- विक्रेता सॉफ्टवेयर का मूल्यांकन
- मौजूदा डेटाबेस का एकीकरण
कृत्रिम बुद्धिमत्ता के क्षेत्र से ज्ञात शक्तिशाली संक्षेपण अवधारणाओं के साथ संबंधात्मक अवधारणाओं के एकीकरण के द्वारा अधिक डेटा का अर्थ ग्रहण करना अर्थ-विज्ञान डेटा मॉडल का सकल लक्ष्य है। यहां विचार उच्च स्तरीय मॉडलिंग के पुरातन तत्वों को डेटा मॉडल के एक अभिन्न अंग के रूप में प्रदान करना है, ताकि वास्तविक-विश्व की स्थितियों के प्रदर्शन में सहायता की जा सके.[8]
इन्हें भी देखें
- डेटा (कम्प्यूटिंग)
- डेटा शब्दकोश
- डेटा मॉडलिंग उपकरण
- दस्तावेज़ मॉडलिंग
- सूचना प्रबंधन
- जानकारीपूर्ण मॉडलिंग
- तीन स्कीमा दृष्टिकोण
- जचमैन फ्रेमवर्क
सन्दर्भ
![]() This article incorporates public domain material from websites or documents of the National Institute of Standards and Technology.
This article incorporates public domain material from websites or documents of the National Institute of Standards and Technology.
- ↑ अ आ इ ई उ ऊ मैथ्यू वेस्ट और जूलियन फोव्लर (1999). डेवेलपिंग हाई क्वालिटी डेटा मॉडलस Archived 2008-12-21 at the वेबैक मशीन. द यूरोपीयन प्रोसेस इंडसट्रीज़ STEP टेक्नीकल लिअसन एक्ज़ीक्यूटिव (EPISTLE).
- ↑ डेटा इंटीग्रेशन शब्दावली Archived 2012-02-18 at the वेबैक मशीन, अमेरिका का परिवहन विभाग, अगस्त 2001.
- ↑ अ आ इ व्हिटेन, जेफरी एल; लोनी डी. बेंटले, केविन सी. डिटमैन. (2004). सिस्टम एनालिसिस ऐंड डिज़ाइन मेथड्स . 6 संस्करण. ISBN 0-256-19906-X.
- ↑ अमेरिकी राष्ट्रीय मानक संस्थान. 1975. ANSI/X3/SPARC स्टडी ग्रुप ऑन डेटा बेस मैनेजमेंट सिस्टम्स; इंटरिम रिपोर्ट . FDT (ACM SIGMOD के बुलेटिन) 7:2.
- ↑ अ आ पॉल आर. स्मिथ और रिचर्ड सर्फटी (1993).कंप्यूटर एडेड सॉफ्टवेयर इंजीनियरिंग (CASE) टूल्स को इस्तेमाल करके स्ट्रेटेजिक प्लैन फॉर कन्फिगेरेशन मैनेजमेंट की योजना बनाना.1993 के लिए कागज़ DOE/कोंट्रेक्टरस और सुविधाएं CAD/CAE यूज़र्स ग्रुप.
- ↑ अ आ इ ई लेन सिल्वरस्टोन, डब्ल्यू. एच. इन्मौन, केंट ग्राज़ानो (2007). द डेटा मॉडल रिसौर्स बुक . विले, 1997. ISBN 0-471-15364-8. tdan.com पर वैन स्कॉट Archived 2010-04-13 at the वेबैक मशीन द्वारा समीक्षित. 1 नवम्बर 2008 को पुनःप्राप्त.
- ↑ अ आ इ ई नैशनल इंस्टीट्यूट ऑफ स्टैण्डर्र्ड्स एण्ड टेक्नोलॉजी (NIST) के कंप्यूटर सिस्टम्स लैबोरेटरी द्वारा IDEF1X की प्रकाशित FIPS पब्लिकेशन 184.21 दिसम्बर 1993.
- ↑ "सिमेंटिक डेटा मॉडलिंग" में: मेटाक्लासेस ऐंड दियर एप्लीकेशन . कंप्यूटर विज्ञान में पुस्तक श्रृंखला व्याख्यान के नोट्स. प्रकाशक स्प्रिंगर बर्लिन / हीडलबर्ग. मात्रा माप 943/1995.
आगे पढ़ें
- जे. एच. बेक्के (1991). सिमेंटिक डेटा मॉडलिंग इन रिलेशनल इनवायरमेंटस
- जॉन विन्सेंट चर्लिस, जोसेफ डी. मगुइरे (2001). मास्टरिंग डेटा मॉडलिंग: अ यूज़र-ड्राइवेन एप्रोच .
- एलन च्मुरा, जे. मार्क हेउमन (2005). लॉजिकल डेटा मॉडलिंग: व्हाट इट इज़ ऐंड हाउ टू डु इट .
- मार्टिन ई. मॉडल (1992). डेटा ऐनालिसिस, डेटा मॉडलिंग और क्लासिफिकेशन .
- एम. पपजोग्लोऊ, स्टेफानो स्पेसकापीट्रा, जहीर तरी (2000). एडवांस इन ऑब्जेक्ट-ओरिएंटटेड डेटा मॉडलिंग .
- जी. लॉरेंस सैंडर्स (1995). डेटा मॉडलिंग
- ग्रीम सी. सिमसन, ग्राहम सी. विट (2005). डेटा मॉडलिंग एसेंशियल्स '''
- ग्रीम सिमसन (2007). डेटा मॉडलिंग: थियोरी ऐंड प्रैक्टिस .
बाहरी कड़ियाँ
- ऐजल/इवोल्यूशनरी डेटा मॉडलिंग
- डेटा मॉडलिंग शब्दकोश
- डेटा मॉडलिंग लेख
- UML में डेटाबेस मॉडलिंग
- मेथड्स & टूल्स में से लेख
- डेटा मॉडलिंग 101
- सिमेंटिक डेटा मॉडलिंग
- सिस्टम डेवेलपमेंट, मेथडालजी और मॉडलिंग टोनी ड्रीव्री द्वारा नोट्स
- ऑब्जेक्ट मैनेजमेंट ग्रुप के प्रस्ताव के लिए अनुरोध - इंफोर्मेशन मैनेजमेंट मेटामॉडल (IMM)