ट्यूरिंग टेस्ट
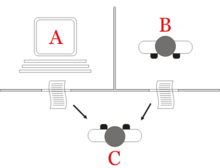
ट्यूरिंग टेस्ट , एलन ट्यूरिंग द्वारा १९५० में विकसित किया गया था, जो मानव के समान, या अविवेच्य के बराबर बुद्धिमान व्यवहार प्रदर्शित करने की मशीन की क्षमता का परीक्षण है। ट्यूरिंग ने प्रस्तावित किया कि एक मानव मूल्यांकनकर्ता एक मानव और एक मशीन के बीच प्राकृतिक भाषा की बातचीत का न्याय करेगा जो मानव जैसी प्रतिक्रिया उत्पन्न करने के लिए डिज़ाइन की गई है। मूल्यांकनकर्ता को पता होगा कि बातचीत में दो भागीदारों में से एक एक मशीन है, और सभी प्रतिभागियों को एक दूसरे से अलग किया जाएगा। बातचीत केवल एक पाठ-चैनल तक सीमित होगी जैसे कंप्यूटर कीबोर्ड और स्क्रीन ताकि परिणाम भाषण के रूप में शब्दों को प्रस्तुत करने की मशीन की क्षमता पर निर्भर न हो। [2] यदि मूल्यांकनकर्ता मज़बूती से मशीन को मानव से नहीं बता सकता है, तो मशीन को परीक्षण पास करने के लिए कहा जाता है। परीक्षण के परिणाम प्रश्नों के सही उत्तर देने के लिए मशीन की क्षमता पर निर्भर नहीं करते हैं, केवल यह कि उनके उत्तर उन लोगों के कितने निकट हैं, जो मानव देते हैं।
ट्यूरिंग ने अपने 1950 के पेपर, " कम्प्यूटिंग मशीनरी एंड इंटेलिजेंस " में टेस्ट की शुरुआत मैनचेस्टर विश्वविद्यालय (ट्यूरिंग, 1950; p) में काम करते हुए की थी। 460)। [3] यह शब्द के साथ खुलता है: "मैं सवाल पर विचार करने का प्रस्ताव, 'मशीनों सोच सकते हैं?' क्योंकि "सोच" को परिभाषित करना मुश्किल है, ट्यूरिंग "किसी अन्य द्वारा प्रश्न को बदलने के लिए चुनता है, जो इसके साथ निकटता से संबंधित है और अपेक्षाकृत अस्पष्ट शब्दों में व्यक्त किया गया है।" [4] ट्यूरिंग का नया प्रश्न है: "क्या कल्पना करने योग्य डिजिटल कंप्यूटर हैं जो नकली गेम में अच्छा करेंगे?" [5] ट्यूरिंग का मानना है कि यह प्रश्न, वास्तव में उत्तर दिया जा सकता है। कागज के शेष हिस्सों में, उन्होंने प्रस्ताव के सभी प्रमुख आपत्तियों के खिलाफ तर्क दिया कि "मशीनें सोच सकती हैं"। [6]
चूंकि ट्यूरिंग ने पहली बार अपना परीक्षण शुरू किया था, यह अत्यधिक प्रभावशाली और व्यापक रूप से आलोचना दोनों साबित हुआ है, और यह कृत्रिम बुद्धि के दर्शन में एक महत्वपूर्ण अवधारणा बन गई है। [7] [8] इनमें से कुछ आलोचनाएँ, जैसे कि जॉन सियरल के चीनी कमरे , अपने आप में विवादास्पद हैं।
इतिहास
दार्शनिक पृष्ठभूमि
यह सवाल कि क्या मशीनों के लिए सोचना संभव है, एक लंबा इतिहास है, जो मन के द्वैतवादी और भौतिकवादी विचारों के बीच के अंतर में मजबूती से घिरा हुआ है। रेने डेसकार्टेस ने ट्यूरिंग टेस्ट के पहलुओं को उनके 1637 के प्रवचन में लिखने के तरीके पर बताया है:
[H]ow many different automata or moving machines can be made by the industry of man [...] For we can easily understand a machine's being constituted so that it can utter words, and even emit some responses to action on it of a corporeal kind, which brings about a change in its organs; for instance, if touched in a particular part it may ask what we wish to say to it; if in another part it may exclaim that it is being hurt, and so on. But it never happens that it arranges its speech in various ways, in order to reply appropriately to everything that may be said in its presence, as even the lowest type of man can do.[9]
यहाँ डेसकार्टेस नोट करते हैं कि ऑटोमेटा मानव इंटरैक्शन का जवाब देने में सक्षम हैं, लेकिन तर्क देते हैं कि इस तरह के ऑटोमेटा किसी भी मानव की राह में उनकी उपस्थिति में कही गई चीजों का उचित जवाब नहीं दे सकते हैं। डेसकार्टेस इसलिए उचित भाषाई प्रतिक्रिया की अपर्याप्तता को परिभाषित करके ट्यूरिंग परीक्षण को पूर्व निर्धारित करता है, जो मानव को ऑटोमेटन से अलग करता है। डेसकार्टेस इस संभावना पर विचार करने में विफल रहता है कि भविष्य में ऑटोमेटा इस तरह की अपर्याप्तता को दूर करने में सक्षम हो सकता है, और इसलिए ट्यूरिंग टेस्ट को इस तरह से प्रस्तावित नहीं करता है, भले ही वह अपने वैचारिक ढांचे और कसौटी को पूरा करता हो।
डेनिस डाइडेरॉट ने अपनी पेन्सिस फिलोसोफिक्स में ट्यूरिंग-टेस्ट की कसौटी बनाई:
"अगर उन्हें एक ऐसा तोता मिल जाए जो हर बात का जवाब दे सके, तो मैं यह दावा करूंगा कि वह बिना किसी हिचकिचाहट के एक बुद्धिमान व्यक्ति होगा।" [10]
इसका मतलब यह नहीं है कि वह इससे सहमत हैं, लेकिन यह उस समय भौतिकवादियों का एक आम तर्क था।
द्वैतवाद के अनुसार, मन गैर-भौतिक है (या, बहुत कम से कम, गैर-भौतिक गुण हैं ) [11] और इसलिए, विशुद्ध रूप से भौतिक शब्दों में समझाया नहीं जा सकता। भौतिकवाद के अनुसार, मन को शारीरिक रूप से समझाया जा सकता है, जो कृत्रिम रूप से पैदा होने वाले मन की संभावनाओं को खोल देता है। [12]
1936 में, दार्शनिक अल्फ्रेड आयर ने अन्य दिमागों के मानक दार्शनिक प्रश्न पर विचार किया: हम कैसे जानते हैं कि अन्य लोगों के पास वही जागरूक अनुभव हैं जो हम करते हैं? अपनी पुस्तक, लैंग्वेज, ट्रुथ एंड लॉजिक में , आयर ने एक सचेत व्यक्ति और अचेतन मशीन के बीच अंतर करने के लिए एक प्रोटोकॉल का सुझाव दिया: "एकमात्र आधार जो कि मुझे सचेत करने के लिए हो सकता है कि जो वस्तु सचेत प्रतीत होती है वह वास्तव में एक जागरूक प्राणी नहीं है, लेकिन केवल एक डमी या मशीन, यह एक अनुभवजन्य परीक्षण को संतुष्ट करने में विफल रहता है जिसके द्वारा चेतना की उपस्थिति या अनुपस्थिति निर्धारित की जाती है। " [13] (यह सुझाव ट्यूरिंग टेस्ट से बहुत मिलता-जुलता है, लेकिन इसका संबंध बुद्धिमत्ता की बजाय चेतना से है। इसके अलावा, यह निश्चित नहीं है कि आयर्स के लोकप्रिय दार्शनिक क्लासिक ट्यूरिंग से परिचित थे। ) दूसरे शब्दों में, कोई चीज सचेत नहीं है अगर वह चेतना परीक्षण में विफल हो जाती है।
एलन ट्यूरिंग
यूनाइटेड किंगडम में शोधकर्ताओं ने कृत्रिम बुद्धि (के क्षेत्र की स्थापना करने से पहले दस साल के लिए "मशीन खुफिया" की खोज की गई थी ऐ 1956 में) अनुसंधान [14] यह के सदस्यों के बीच एक आम विषय था अनुपात क्लब , जो ब्रिटिश साइबरनेटिक्स और इलेक्ट्रॉनिक्स शोधकर्ताओं का एक अनौपचारिक समूह थे, जिसमें एलन ट्यूरिंग शामिल थे, जिनके बाद परीक्षण का नाम दिया गया। [15]
ट्यूरिंग, विशेष रूप से, कम से कम 1941 [16] बाद से मशीन इंटेलिजेंस की धारणा से निपट रहे थे और "कंप्यूटर इंटेलिजेंस" के शुरुआती ज्ञात उल्लेख 1947 में उनके द्वारा किए गए थे। [17] ट्यूरिंग की रिपोर्ट में, "इंटेलिजेंट मशीनरी" ", [18] उन्होंने जांच की" इस सवाल का कि क्या मशीनरी के लिए बुद्धिमान व्यवहार दिखाना संभव है या नहीं " [19] और, उस जांच के हिस्से के रूप में, प्रस्तावित किया गया कि उनके बाद के परीक्षणों में अग्रदूत माना जा सकता है:
एक पेपर मशीन को तैयार करना मुश्किल नहीं है जो शतरंज का बहुत बुरा खेल नहीं खेलेगी। अब प्रयोग के लिए विषय के रूप में तीन पुरुष प्राप्त करें। A, B और C. A और C बल्कि घटिया शतरंज के खिलाड़ी हैं, B वह ऑपरेटर है जो पेपर मशीन का काम करता है। ... दो कमरों का उपयोग चालों को संप्रेषित करने के लिए कुछ व्यवस्था के साथ किया जाता है, और एक खेल C और A या पेपर मशीन के बीच खेला जाता है। C को यह बताना काफी मुश्किल हो सकता है कि वह कौन सा खेल रहा है। [20]
" कम्प्यूटिंग मशीनरी एंड इंटेलिजेंस " ( 1950 ) मशीन बुद्धि पर विशेष रूप से ध्यान केंद्रित करने के लिए ट्यूरिंग द्वारा पहला प्रकाशित पत्र था। ट्यूरिंग दावा के साथ 1950 कागज शुरू होता है, "मैं सवाल पर विचार करने का प्रस्ताव 'मशीनों सोच सकते हैं?'" [4] वह प्रकाश डाला गया के रूप में, इस तरह के एक प्रश्न के परंपरागत दृष्टिकोण के साथ शुरू करने के लिए है परिभाषाओं , दोनों शब्दों "मशीन" को परिभाषित करने और "बुद्धि"। ट्यूरिंग ऐसा नहीं करने का विकल्प चुनता है; इसके बजाय वह प्रश्न को एक नए के साथ प्रतिस्थापित करता है, "जो इसके साथ निकटता से संबंधित है और अपेक्षाकृत अस्पष्ट शब्दों में व्यक्त किया गया है।" [4] संक्षेप में, वह "क्या मशीनें सोच सकती हैं" से प्रश्न को बदलने का प्रस्ताव करती हैं? "क्या मशीनें ऐसा कर सकती हैं जो हम (सोच के अनुसार) कर सकते हैं?" [21] नए प्रश्न का लाभ, ट्यूरिंग का तर्क है, यह "एक व्यक्ति की भौतिक और बौद्धिक क्षमता के बीच एक काफी तेज रेखा खींचता है।" [22] इस दृष्टिकोण को प्रदर्शित करने के लिए ट्यूरिंग ने एक पार्टी गेम से प्रेरित एक परीक्षा का प्रस्ताव रखा, जिसे "नकल खेल" के रूप में जाना जाता है, जिसमें एक पुरुष और एक महिला अलग-अलग कमरों में जाते हैं और मेहमान प्रश्नों की एक श्रृंखला लिखकर और टाइपराइटर पढ़कर उन्हें बताने की कोशिश करते हैं जवाब वापस भेज दिया। इस गेम में पुरुष और महिला दोनों का उद्देश्य मेहमानों को यह विश्वास दिलाना है कि वे दूसरे हैं। (हुमा शाह का तर्क है कि गेम के इस दो-मानव संस्करण को ट्यूरिंग द्वारा केवल मशीन-मानव प्रश्न-उत्तर परीक्षण के लिए पाठक को पेश करने के लिए प्रस्तुत किया गया था। [23] ) ट्यूरिंग ने खेल के अपने नए संस्करण का वर्णन इस प्रकार किया है:
हम अब सवाल पूछते हैं, "जब एक मशीन इस खेल में ए का हिस्सा लेती है तो क्या होगा?" क्या पूछताछकर्ता गलत तरीके से निर्णय लेगा जब खेल को इस तरह खेला जाता है जैसे वह तब करता है जब खेल पुरुष और महिला के बीच खेला जाता है? ये प्रश्न हमारे मूल को प्रतिस्थापित करते हैं, "क्या मशीनें सोच सकती हैं?" [22]
बाद में पेपर ट्यूरिंग में एक "समतुल्य" वैकल्पिक सूत्रीकरण का सुझाव दिया गया जिसमें केवल एक कंप्यूटर और एक आदमी के साथ बातचीत कर रहे न्यायाधीश शामिल थे। [24] जबकि इन योगों में से कोई भी ट्यूरिंग परीक्षण के संस्करण से बिल्कुल मेल नहीं खाता है, जो आज अधिक सामान्यतः ज्ञात है, उन्होंने १ ९ ५२ में एक तीसरे का प्रस्ताव रखा। इस संस्करण में, जो ट्यूरिंग ने बीबीसी रेडियो प्रसारण में चर्चा की, एक जूरी ने एक कंप्यूटर के सवाल पूछे और कंप्यूटर की भूमिका जूरी का एक महत्वपूर्ण अनुपात बनाने के लिए मानती है कि यह वास्तव में एक आदमी है। [25]
ट्यूरिंग के पेपर में नौ संवेदी आपत्तियों पर विचार किया गया, जिसमें कृत्रिम बुद्धिमत्ता के खिलाफ सभी प्रमुख तर्क शामिल हैं जो कि पेपर प्रकाशित होने के बाद के वर्षों में उठाए गए हैं (देखें " कम्प्यूटिंग मशीनरी और इंटेलिजेंस ")। [6]
एलीज़ा और पैरी
1966 में, जोसेफ वेइसनबाम ने एक कार्यक्रम बनाया, जो ट्यूरिंग टेस्ट पास करने के लिए दिखाई दिया। प्रोग्राम, जिसे ELIZA के रूप में जाना जाता है, ने कीवर्ड के लिए उपयोगकर्ता की टाइप की गई टिप्पणियों की जांच करके काम किया। यदि कोई कीवर्ड पाया जाता है, तो उपयोगकर्ता की टिप्पणियों को बदलने वाला नियम लागू किया जाता है, और परिणामी वाक्य वापस कर दिया जाता है। यदि कोई कीवर्ड नहीं मिला है, तो एलिज़ा या तो जेनेरिक रिपोस्ट के साथ प्रतिक्रिया करता है या पहले की टिप्पणियों में से एक को दोहराकर। [26] इसके अलावा, वीज़ेनबाउम ने एक रोजरियन मनोचिकित्सक के व्यवहार को दोहराने के लिए एलिजा को विकसित किया, जिससे एलिज़ा को "वास्तविक दुनिया के लगभग कुछ भी नहीं जानने के लिए स्वतंत्र मानने" की अनुमति मिली। [27] techniques [27] इन तकनीकों के साथ, वीज़ेनबाउम का कार्यक्रम कुछ लोगों को यह विश्वास दिलाने में सक्षम था कि वे एक वास्तविक व्यक्ति से बात कर रहे हैं, कुछ विषयों के साथ "यह समझाने के लिए बहुत कठिन है कि एलिज़ा [...] मानव नहीं है ।" [27] इस प्रकार, एलिज़ा का दावा कुछ कार्यक्रमों में से एक है (शायद पहला) जो ट्यूरिंग परीक्षण को पास करने में सक्षम है, [27] test [27] [28] भले ही यह दृश्य अत्यधिक विवादास्पद है ( नीचे देखें )।
केनेथ कॉलबी ने 1972 में PARRY बनाया, एक कार्यक्रम जिसे "रवैया के साथ एलिज़ा" के रूप में वर्णित किया गया था। [29] इसने विएज़ानबौम द्वारा नियोजित समान (यदि अधिक उन्नत) दृष्टिकोण का उपयोग करते हुए, एक पागल स्किज़ोफ्रेनिक के व्यवहार को मॉडल करने का प्रयास किया। कार्य को मान्य करने के लिए, ट्यूरिंग परीक्षण की भिन्नता का उपयोग करके 1970 के दशक की शुरुआत में पैरी का परीक्षण किया गया था। अनुभवी मनोचिकित्सकों के एक समूह ने टेलीप्रिंटर्स के माध्यम से पैरी चलाने वाले वास्तविक रोगियों और कंप्यूटरों के संयोजन का विश्लेषण किया। 33 मनोचिकित्सकों के एक अन्य समूह को बातचीत के टेप दिखाए गए थे। फिर दो समूहों को यह पहचानने के लिए कहा गया कि कौन से "रोगी" मानव थे और कौन से कंप्यूटर प्रोग्राम थे। [30] मनोचिकित्सक केवल ४ The प्रतिशत समय तक ही सही पहचान कर पाए - यादृच्छिक अनुमान के अनुरूप एक आंकड़ा। [31]
21 वीं सदी में, इन कार्यक्रमों के संस्करण (जिसे अब " चीटरबॉट्स " के रूप में जाना जाता है) लोगों को बेवकूफ बनाते हैं। "CyberLover", एक मैलवेयर प्रोग्राम, इंटरनेट उपयोगकर्ताओं पर "उन्हें उनकी पहचान के बारे में जानकारी प्रकट करने या एक वेब साइट पर जाने के लिए नेतृत्व करने के लिए प्रेरित करता है जो उनके कंप्यूटर पर दुर्भावनापूर्ण सामग्री वितरित करेगा"। [32] कार्यक्रम एक "वेलेंटाइन-जोखिम" के रूप में उभरा है जो लोगों के साथ छेड़खानी कर रहा है "अपने व्यक्तिगत डेटा एकत्र करने के लिए रिश्तों को ऑनलाइन मांग रहा है"। [33]
चीनी कमरा
जॉन सियरले के 1980 के पेपर माइंड्स, दिमाग और प्रोग्राम्स ने " चीनी कमरे " के प्रयोग का प्रस्ताव रखा और तर्क दिया कि ट्यूरिंग टेस्ट का उपयोग यह निर्धारित करने के लिए नहीं किया जा सकता है कि क्या मशीन सोच सकती है। Searle ने कहा कि सॉफ्टवेयर (जैसे कि एलिज़ा) ट्यूरिंग टेस्ट को केवल उन प्रतीकों में हेरफेर करके पास कर सकता है जिनकी उन्हें कोई समझ नहीं थी। समझ के बिना, उन्हें उसी अर्थ में "सोच" के रूप में वर्णित नहीं किया जा सकता है जो लोग हैं। इसलिए, सियरले का निष्कर्ष है, ट्यूरिंग परीक्षण यह साबित नहीं कर सकता है कि एक मशीन सोच सकती है। [34] ट्यूरिंग टेस्ट की तरह ही, शियरल के तर्क की व्यापक रूप से आलोचना हुई [35] और अत्यधिक समर्थन किया गया। [36]
मन के दर्शन पर काम कर रहे Searle और अन्य जैसे तर्क बुद्धि की प्रकृति, बुद्धिमान मशीनों की संभावना और ट्यूरिंग परीक्षण के मूल्य के बारे में अधिक गहन बहस छिड़ गई जो 1980 और 1990 के दशक के दौरान जारी रही। [37]
Loebner Prize
Loebner Prize नवंबर 1991 में आयोजित पहली प्रतियोगिता के साथ व्यावहारिक ट्यूरिंग परीक्षणों के लिए एक वार्षिक मंच प्रदान करता है। [38] यह ह्यूग Loebner द्वारा लिखित है । संयुक्त राज्य अमेरिका के मैसाचुसेट्स में कैंब्रिज सेंटर फॉर बिहेवियरल स्टडीज़ ने 2003 की प्रतियोगिता तक के पुरस्कारों का आयोजन किया। जैसा कि लोएबनेर ने इसका वर्णन किया है, एक कारण प्रतियोगिता का निर्माण किया गया था, एआई अनुmamiसंधान की स्थिति को आगे बढ़ाने के लिए, कम से कम भाग में, क्योंकि किसी ने भी चर्चा करने के 40 वर्षों के बावजूद ट्यूरिंग परीक्षण को लागू करने के लिए कदम नहीं उठाए थे। [39]
1991 में पहली Loebner Prize प्रतियोगिता ने ट्यूरिंग परीक्षण की व्यवहार्यता और इसे आगे बढ़ाने के मूल्य की नए सिरे से चर्चा की, लोकप्रिय प्रेस [40] और शिक्षाविद दोनों में। [41] पहली प्रतियोगिता बिना पहचान के बुद्धिमत्ता के साथ नासमझ कार्यक्रम द्वारा जीती गई जो गलत पहचान बनाने में भोले-भाले पूछताछकर्ताओं को बेवकूफ बनाने में कामयाब रही। इसने ट्यूरिंग टेस्ट की कई कमियों को उजागर किया ( नीचे चर्चा की गई ): विजेता कम से कम भाग में जीता, क्योंकि यह "मानव टाइपिंग त्रुटियों की नकल करने" में सक्षम था; [40] सोचे-समझे पूछताछ करने वालों को आसानी से बेवकूफ बना दिया गया; [41] और एआई में कुछ शोधकर्ताओं को यह महसूस करने के लिए प्रेरित किया गया है कि परीक्षण केवल अधिक उपयोगी अनुसंधान से एक व्याकुलता है। [42]
रजत (केवल पाठ) और स्वर्ण (ऑडियो और दृश्य) पुरस्कार कभी नहीं जीते गए। हालांकि, प्रतियोगिता ने कंप्यूटर प्रणाली के लिए हर साल कांस्य पदक से सम्मानित किया है, जो कि न्यायाधीशों की राय में, उस वर्ष की प्रविष्टियों के बीच "सबसे मानवीय" संवादी व्यवहार को प्रदर्शित करता है। आर्टिफिशियल लिंग्विस्टिक इंटरनेट कंप्यूटर एंटिटी (ALICE) ने हाल के दिनों (2000, 2001, 2004) में तीन बार कांस्य पुरस्कार जीता है। लर्निंग एआई जाबेरवाकी ने 2005 और 2006 में जीता।
लॉबनेर पुरस्कार संवादी खुफिया परीक्षण करता है; विजेता आमतौर पर चैट्टरबोट प्रोग्राम या आर्टिफिशियल कन्वर्सेशन एंटिटीज़ (ACE) हैं । प्रारंभिक Loebner Prize नियम प्रतिबंधित बातचीत: प्रत्येक प्रविष्टि और छिपे हुए मानव ने एक ही विषय पर बातचीत की, [43] इस प्रकार पूछताछकर्ता प्रति इकाई बातचीत पर सवाल उठाने की एक पंक्ति तक सीमित रहे। 1995 के Loebner Prize के लिए प्रतिबंधित वार्तालाप नियम हटा दिया गया था। न्यायाधीश और इकाई के बीच बातचीत की अवधि लोब्नर पुरस्कारों में विविध है। लॉबनेर 2003 में, सरे विश्वविद्यालय में, प्रत्येक पूछताछकर्ता को एक इकाई, मशीन या छिपे-मानव के साथ बातचीत करने के लिए पांच मिनट की अनुमति दी गई थी। 2004 और 2007 के बीच, लोएबनेर पुरस्कारों में अनुमति दिए गए इंटरैक्शन का समय बीस मिनट से अधिक था।
संस्करण

शाऊल ट्रेगर का तर्क है कि ट्यूरिंग परीक्षण के कम से कम तीन प्राथमिक संस्करण हैं, जिनमें से दो "कम्प्यूटिंग मशीनरी और इंटेलिजेंस" में पेश किए जाते हैं और एक जिसे वह "मानक व्याख्या" के रूप में वर्णित करता है। [44] हालांकि इस बात को लेकर कुछ बहस है कि क्या "मानक व्याख्या" का वर्णन ट्यूरिंग द्वारा किया गया है या इसके बजाय, उसके कागज के गलत प्रचार के आधार पर, इन तीन संस्करणों को समकक्ष नहीं माना जाता है, [44] और उनकी ताकत और कमजोरियाँ अलग। [45]
हुमा शाह बताती हैं कि ट्यूरिंग खुद इस बात से चिंतित थे कि क्या कोई मशीन सोच सकती है और यह जांचने के लिए एक सरल तरीका प्रदान कर रही है: मानव-मशीन सवाल-जवाब सत्रों के माध्यम से। [46] there [46] शाह का तर्क है कि एक नकल का खेल है जिसका वर्णन ट्यूरिंग दो अलग-अलग तरीकों से किया जा सकता है: क) एक-से-एक इंटररोगेटर-मशीन परीक्षण, और बी) एक साथ मानव के साथ मशीन की तुलना, दोनों समानांतर में पूछताछ एक पूछताछकर्ता। [23] चूंकि ट्यूरिंग परीक्षण प्रदर्शन क्षमता में अविभाज्यता का परीक्षण है, इसलिए मौखिक संस्करण स्वाभाविक रूप से मानव प्रदर्शन क्षमता, मौखिक और साथ ही अशाब्दिक (रोबोटिक) सभी के लिए सामान्य रूप से सामान्य हो जाता है। [47]
नकल का खेल
ट्यूरिंग के मूल लेख में तीन खिलाड़ियों को शामिल करने वाले एक साधारण पार्टी गेम का वर्णन किया गया है। प्लेयर ए पुरुष है, खिलाड़ी बी महिला है और खिलाड़ी सी (जो पूछताछकर्ता की भूमिका निभाता है) या तो सेक्स का है। नकली गेम में, खिलाड़ी C या तो खिलाड़ी A या खिलाड़ी B को देखने में असमर्थ है, और केवल लिखित नोट्स के माध्यम से उनसे संवाद कर सकता है। खिलाड़ी A और खिलाड़ी B के प्रश्न पूछकर, खिलाड़ी C यह निर्धारित करने की कोशिश करता है कि दोनों में से कौन पुरुष है और कौन सी महिला है। खिलाड़ी ए की भूमिका गलत निर्णय लेने में पूछताछकर्ता को धोखा देने की है, जबकि खिलाड़ी बी सही बनाने में पूछताछकर्ता की सहायता करने का प्रयास करता है। [7]
ट्यूरिंग तब पूछता है:
जब कोई मशीन इस खेल में A का भाग लेती है तो क्या होगा? क्या पूछताछकर्ता गलत तरीके से निर्णय लेगा जब खेल को इस तरह खेला जाता है जैसे वह तब करता है जब खेल पुरुष और महिला के बीच खेला जाता है? ये प्रश्न हमारे मूल को प्रतिस्थापित करते हैं, "क्या मशीनें सोच सकती हैं?" [22]

दूसरा संस्करण बाद में ट्यूरिंग के 1950 के पेपर में दिखाई दिया। मूल नकली गेम टेस्ट के समान, कंप्यूटर द्वारा खिलाड़ी ए की भूमिका निभाई जाती है। हालांकि, खिलाड़ी बी की भूमिका एक महिला के बजाय एक पुरुष द्वारा की जाती है।
आइए हम एक विशेष डिजिटल कंप्यूटर सी पर अपना ध्यान केंद्रित करें । क्या यह सच है कि इस कंप्यूटर को पर्याप्त भंडारण करने के लिए संशोधित करके, इसकी कार्रवाई की गति को बढ़ाकर, और इसे एक उचित कार्यक्रम प्रदान करके, C को संतोषजनक ढंग से खेलने के लिए बनाया जा सकता है नकल के खेल में A, B का हिस्सा एक आदमी द्वारा लिया जा रहा है? [22]
इस संस्करण में, खिलाड़ी A (कंप्यूटर) और खिलाड़ी B, गलत निर्णय लेने में पूछताछकर्ता को बरगला रहे हैं।
मानक व्याख्या
सामान्य समझ यह है कि ट्यूरिंग टेस्ट का उद्देश्य विशेष रूप से यह निर्धारित करने के लिए नहीं है कि क्या एक कंप्यूटर एक पूछताछकर्ता को यह विश्वास दिलाने में सक्षम है कि यह एक मानव है, बल्कि यह है कि क्या एक कंप्यूटर एक मानव की नकल कर सकता है। [7] हालांकि कुछ विवाद है कि क्या इस व्याख्या ट्यूरिंग द्वारा इरादा था है, Sterrett मानना है कि यह था [48] और इस प्रकार, यह एक साथ दूसरे संस्करण इंगित करते हुए इस तरह के Traiger के रूप में दूसरों,, ऐसा नहीं [44] - इसके बाद भी "मानक व्याख्या" के रूप में देखा जा सकता है। इस संस्करण में, खिलाड़ी A कंप्यूटर और खिलाड़ी B दोनों में से एक व्यक्ति है। पूछताछकर्ता की भूमिका यह निर्धारित करने के लिए नहीं है कि कौन सा पुरुष है और कौन महिला है, लेकिन जो एक कंप्यूटर है और जो एक मानव है। [49] मानक व्याख्या के साथ मूलभूत मुद्दा यह है कि पूछताछकर्ता यह अंतर नहीं कर सकता कि कौन सा उत्तरदाता मानवीय है, और कौन सा मशीन है। अवधि के बारे में मुद्दे हैं, लेकिन मानक व्याख्या आम तौर पर इस सीमा को कुछ ऐसा मानती है जो उचित होना चाहिए।
नकली खेल बनाम मानक ट्यूरिंग टेस्ट
विवाद ट्यूरिंग के वैकल्पिक योगों में से एक पर विवाद पैदा हो गया है। [48] Sterrett का तर्क है कि दो अलग-अलग परीक्षण उसकी 1950 कागज और कि से निकाला जा सकता, ट्यूरिंग की टिप्पणी गति, वे नहीं के बराबर हैं। परीक्षण जो पार्टी गेम को नियोजित करता है और सफलता की आवृत्तियों की तुलना करता है, उसे "मूल नकल खेल परीक्षण" कहा जाता है, जबकि परीक्षण में एक मानव और एक मशीन के साथ बातचीत करने वाले मानव न्यायाधीश को "स्टैंडर्ड ट्यूरिंग टेस्ट" कहा जाता है, यह देखते हुए कि स्टरेट ने नकली गेम के दूसरे संस्करण के बजाय "मानक व्याख्या" के साथ इसकी बराबरी की है। Sterrett सहमत हैं कि मानक ट्यूरिंग टेस्ट (STT) में वे समस्याएं हैं जो इसके आलोचकों का हवाला देती हैं, लेकिन उन्हें लगता है कि इसके विपरीत, मूल नकली गेम टेस्ट (OIG परीक्षण) को परिभाषित किया गया है, जो उनमें से कई के लिए प्रतिरक्षात्मक है, एक महत्वपूर्ण अंतर के कारण। एसटीटी, यह मानव प्रदर्शन की कसौटी पर समानता नहीं करता है, भले ही यह मशीन बुद्धि के लिए एक मानदंड स्थापित करने में मानव प्रदर्शन को नियोजित करता है। एक व्यक्ति OIG परीक्षण को विफल कर सकता है, लेकिन यह तर्क दिया जाता है कि यह बुद्धि की परीक्षा का एक गुण है जो विफलता संसाधनशीलता की कमी को इंगित करता है: OIG परीक्षण के लिए बुद्धिमत्ता से जुड़े संसाधन की आवश्यकता होती है न कि केवल "मानव संवादी व्यवहार का अनुकरण"। OIG परीक्षण की सामान्य संरचना का उपयोग नकली गेम के गैर-मौखिक संस्करणों के साथ भी किया जा सकता है। [50]
फिर भी अन्य लेखकों [51] ने ट्यूरिंग की व्याख्या करते हुए कहा है कि नकल खेल ही वह परीक्षा है, जिसमें यह निर्दिष्ट किए बिना कि ट्यूरिंग के कथन को कैसे ध्यान में रखा जाए कि जिस परीक्षा में उसने नकल के खेल के पार्टी संस्करण का उपयोग करने का प्रस्ताव किया है वह तुलनात्मक की कसौटी पर आधारित है उस नकल के खेल में सफलता की आवृत्ति, खेल के एक दौर में सफल होने की क्षमता के बजाय।
Saygin ने सुझाव दिया है कि शायद मूल खेल कम पक्षपाती प्रायोगिक डिजाइन का प्रस्ताव करने का एक तरीका है क्योंकि यह कंप्यूटर की भागीदारी को छुपाता है। [52] नकल के खेल में एक "सामाजिक हैक" भी शामिल है जो मानक व्याख्या में नहीं पाया जाता है, क्योंकि खेल में कंप्यूटर और पुरुष मानव दोनों को किसी ऐसे व्यक्ति के रूप में खेलने की आवश्यकता होती है जो वे नहीं हैं। [53]
क्या पूछताछकर्ता को कंप्यूटर के बारे में पता होना चाहिए?
किसी भी प्रयोगशाला परीक्षण का एक महत्वपूर्ण टुकड़ा यह है कि एक नियंत्रण होना चाहिए। ट्यूरिंग कभी स्पष्ट नहीं करता है कि क्या उसके परीक्षणों में पूछताछकर्ता को पता है कि प्रतिभागियों में से एक कंप्यूटर है। हालांकि, अगर कोई ऐसी मशीन थी जिसमें ट्यूरिंग टेस्ट पास करने की क्षमता थी, तो यह मान लेना सुरक्षित होगा कि डबल ब्लाइंड कंट्रोल जरूरी होगा।
मूल नकल के खेल में लौटने के लिए, वह केवल यह कहता है कि खिलाड़ी A को मशीन से बदला जाना है, न कि उस खिलाड़ी C को इस प्रतिस्थापन के बारे में सूचित किया जाना है। [22] जब कोल्बी, एफडी हिलफ, एस वेबर और एडी क्रेमर ने पैरी का परीक्षण किया, तो उन्होंने यह मानकर ऐसा किया कि पूछताछकर्ताओं को यह जानने की जरूरत नहीं है कि जिन लोगों से साक्षात्कार लिया गया है, उनमें से एक या अधिक को पूछताछ के दौरान एक कंप्यूटर था। [54] अइसे सयागिन के रूप में, पीटर स्विरस्की, [55] और अन्य लोगों ने प्रकाश डाला है, इससे परीक्षण के कार्यान्वयन और परिणाम पर बहुत फर्क पड़ता है। [7] लोकेनर के एक-से-एक (पूछताछकर्ता-छिपे हुए वार्ताकार) के ट्रांसक्रिप्शंस का उपयोग करते हुए गिएरेन मैक्सिम उल्लंघनों को देखते हुए एक प्रायोगिक अध्ययन, 1994-1999 के बीच एआई प्रतियोगिताओं के लिए पुरस्कार, आइसे सायजिन प्रतिभागियों की प्रतिक्रियाओं के बीच महत्वपूर्ण अंतर था जो जानते थे और नहीं कंप्यूटर शामिल होने के बारे में जानें। [56]
ताकत
ट्रैक्टिबिलिटी और सरलता
ट्यूरिंग परीक्षण की शक्ति और अपील इसकी सादगी से प्राप्त होती है। मन , मनोविज्ञान और आधुनिक तंत्रिका विज्ञान के दर्शन "बुद्धिमत्ता" और "सोच" की परिभाषा प्रदान करने में असमर्थ रहे हैं जो मशीनों के लिए पर्याप्त रूप से सटीक और सामान्य हैं। ऐसी परिभाषाओं के बिना, कृत्रिम बुद्धि के दर्शन के केंद्रीय प्रश्नों का उत्तर नहीं दिया जा सकता है। ट्यूरिंग टेस्ट, भले ही अपूर्ण हो, कम से कम कुछ ऐसा प्रदान करता है जिसे वास्तव में मापा जा सकता है। जैसे, यह एक कठिन दार्शनिक प्रश्न का उत्तर देने का एक व्यावहारिक प्रयास है।
विषय वस्तु की चौड़ाई
परीक्षण का प्रारूप पूछताछकर्ता को मशीन को विभिन्न प्रकार के बौद्धिक कार्यों को देने की अनुमति देता है। ट्यूरिंग ने लिखा है कि "प्रश्न और उत्तर पद्धति मानव प्रयास के लगभग किसी एक क्षेत्र को शुरू करने के लिए उपयुक्त प्रतीत होती है, जिसमें हम शामिल होना चाहते हैं।" [57] ५eland [57] जॉन हैगलैंड ने कहा कि "शब्दों को समझना पर्याप्त नहीं है; आपको विषय को भी समझना होगा।" [58]
एक अच्छी तरह से डिज़ाइन किए गए ट्यूरिंग टेस्ट को पास करने के लिए, मशीन को प्राकृतिक भाषा , कारण , ज्ञान का उपयोग करना और सीखना होगा । वीडियो इनपुट शामिल करने के लिए परीक्षण को बढ़ाया जा सकता है, साथ ही एक "हैच" भी जिसके माध्यम से वस्तुओं को पारित किया जा सकता है: यह मशीन को दृष्टि और रोबोटिक्स के कौशल को प्रदर्शित करने के लिए मजबूर करेगा। साथ में, ये लगभग सभी प्रमुख समस्याओं का प्रतिनिधित्व करते हैं जिन्हें कृत्रिम बुद्धिमत्ता अनुसंधान हल करना चाहते हैं। [59]
Feigenbaum परीक्षण को ट्यूरिंग परीक्षण के लिए उपलब्ध विषयों की व्यापक श्रेणी का लाभ उठाने के लिए डिज़ाइन किया गया है। यह ट्यूरिंग के सवाल-जवाब के खेल का एक सीमित रूप है जो मशीन की तुलना साहित्य या रसायन विज्ञान जैसे विशिष्ट क्षेत्रों में विशेषज्ञों की क्षमताओं के खिलाफ करता है। आईबीएम की वाटसन मशीन ने मानव ज्ञान बनाम मशीन टेलीविज़न क्विज़ शो में एक व्यक्ति को सफलता प्राप्त की, जोश में है! [60] ]
भावनात्मक और सौंदर्य बुद्धि पर जोर
जैसा कि कैम्ब्रिज गणित में स्नातक का सम्मान करता है, ट्यूरिंग से कुछ उच्च तकनीकी क्षेत्र में विशेषज्ञ ज्ञान की आवश्यकता वाले कंप्यूटर इंटेलिजेंस के एक परीक्षण का प्रस्ताव करने की उम्मीद की जा सकती थी, और इस प्रकार विषय के लिए और अधिक हाल के दृष्टिकोण की आशंका थी। इसके बजाय, जैसा कि पहले ही उल्लेख किया गया है, जो परीक्षण उन्होंने अपने सेमिनल 1950 के पेपर में वर्णित किया है, कंप्यूटर को एक सामान्य पार्टी गेम में सफलतापूर्वक प्रतिस्पर्धा करने में सक्षम होने की आवश्यकता है, और इसके साथ-साथ प्रश्नों की एक श्रृंखला का जवाब देने में विशिष्ट व्यक्ति का प्रदर्शन महिला प्रतियोगी होने का ढोंग करना।
विषयों के सबसे प्राचीन में से एक के रूप में मानव यौन द्विरूपता की स्थिति को देखते हुए, यह इस प्रकार उपरोक्त परिदृश्य में निहित है कि जिन सवालों का जवाब दिया जाना है उनमें न तो विशेष तथ्यात्मक ज्ञान और न ही सूचना प्रसंस्करण तकनीक शामिल होगी। कंप्यूटर के लिए चुनौती, बल्कि, महिला की भूमिका के लिए सहानुभूति का प्रदर्शन करना होगा, और साथ ही साथ एक विशिष्ट सौंदर्य संवेदना को प्रदर्शित करना होगा - दोनों गुण संवाद के इस स्निपेट में प्रदर्शित हैं, जो कि ट्यूरिंग ने कल्पना की है:
- प्रश्नकर्ता: विल एक्स कृपया मुझे उसके बालों की लंबाई बताएं?
- कंटेस्टेंट: मेरे बाल छिल गए हैं, और सबसे लंबा स्ट्रैंड लगभग नौ इंच लंबा है।
जब ट्यूरिंग ने अपने एक काल्पनिक संवाद में कुछ विशेष ज्ञान का परिचय दिया, तो विषय गणित या इलेक्ट्रॉनिक्स नहीं है, लेकिन कविता:
- पूछताछकर्ता: आपके सॉनेट की पहली पंक्ति में, जो पढ़ता है, "क्या मैं आपकी तुलना एक गर्मी के दिन से करूंगा," वसंत का दिन "अच्छा नहीं होगा या बेहतर होगा?
- गवाह: यह स्कैन नहीं होगा।
- पूछताछकर्ता: "सर्दियों का दिन कैसा है।" यह सब ठीक होगा।
- गवाह: हाँ, लेकिन कोई भी सर्दियों के दिन की तुलना नहीं करना चाहता है।
इस प्रकार ट्यूरिंग एक बार फिर एक कृत्रिम बुद्धि के घटकों के रूप में सहानुभूति और सौंदर्य संवेदनशीलता में उनकी रुचि को प्रदर्शित करता है; और एआई रन एमक से खतरे की बढ़ती जागरूकता के मद्देनजर, [61] यह सुझाव दिया गया है [62] कि यह ध्यान संभवतः ट्यूरिंग के हिस्से पर एक महत्वपूर्ण अंतर्ज्ञान का प्रतिनिधित्व करता है, अर्थात, भावनात्मक और सौंदर्य बुद्धि एक महत्वपूर्ण भूमिका निभाएगी एक " अनुकूल एआई " के निर्माण में। हालांकि, यह भी ध्यान दिया जाता है कि जो भी प्रेरणा ट्यूरिंग को इस दिशा में उधार देने में सक्षम हो सकती है, वह उसकी मूल दृष्टि के संरक्षण पर निर्भर करती है, जो आगे कहती है, कि ट्यूरिंग टेस्ट की "मानक व्याख्या" का उद्घोष। , जो केवल एक विवेकपूर्ण बुद्धि पर ध्यान केंद्रित करता है - उसे कुछ सावधानी के साथ माना जाना चाहिए।
कमजोरियों
ट्यूरिंग ने स्पष्ट रूप से नहीं बताया कि ट्यूरिंग परीक्षण का उपयोग बुद्धि, या किसी अन्य मानव गुणवत्ता के माप के रूप में किया जा सकता है। वह "थिंक" शब्द का एक स्पष्ट और समझने योग्य विकल्प प्रदान करना चाहता था, जिसे वह तब "थिंकिंग मशीन" की संभावना की आलोचनाओं का जवाब देने और उन तरीकों का सुझाव देने के लिए उपयोग कर सकता है जो अनुसंधान आगे बढ़ सकते हैं।
फिर भी, ट्यूरिंग परीक्षण को मशीन की "सोचने की क्षमता" या इसके "बुद्धिमत्ता" के उपाय के रूप में प्रस्तावित किया गया है। इस प्रस्ताव को दार्शनिकों और कंप्यूटर वैज्ञानिकों दोनों से आलोचना मिली है। यह मानता है कि एक इंट्रोगेटर निर्धारित कर सकता है कि क्या मशीन मानव व्यवहार के साथ अपने व्यवहार की तुलना करके "सोच" रही है। इस धारणा के हर तत्व पर सवाल उठाया गया है: पूछताछकर्ता के फैसले की विश्वसनीयता, केवल व्यवहार की तुलना करने का मूल्य और मशीन की मानव के साथ तुलना करने का मूल्य। इन और अन्य विचारों के कारण, कुछ AI शोधकर्ताओं ने अपने क्षेत्र में परीक्षण की प्रासंगिकता पर सवाल उठाया है।
सामान्य रूप से मानव बुद्धि बनाम बुद्धिमत्ता

ट्यूरिंग टेस्ट सीधे परीक्षण नहीं करता है कि क्या कंप्यूटर समझदारी से व्यवहार करता है। यह केवल परीक्षण करता है कि क्या कंप्यूटर एक इंसान की तरह व्यवहार करता है। चूँकि मानव व्यवहार और बुद्धिमान व्यवहार बिलकुल एक समान नहीं हैं, परीक्षण दो तरीकों से बुद्धि को सही ढंग से मापने में विफल हो सकता है:
- कुछ मानव व्यवहार अनजाने में होते हैं
- ट्यूरिंग परीक्षण के लिए आवश्यक है कि मशीन सभी मानवीय व्यवहारों को निष्पादित करने में सक्षम हो, चाहे वे बुद्धिमान हों। यह उन व्यवहारों के लिए भी परीक्षण करता है, जिन्हें बुद्धिमान नहीं माना जा सकता है, जैसे अपमान करने की संवेदनशीलता, [63] झूठ बोलने का प्रलोभन या, बस, टाइपिंग गलतियों की एक उच्च आवृत्ति। यदि कोई मशीन इन अनजाने व्यवहारों का विस्तार से अनुकरण नहीं कर सकती है तो यह परीक्षण में विफल रहता है।
- अर्थशास्त्री द्वारा यह आपत्ति 1992 में पहले Loebner Prize प्रतियोगिता के तुरंत बाद प्रकाशित " कृत्रिम मूर्खता " नामक एक लेख में उठाई गई थी। इस लेख में कहा गया है कि पहले Loebner विजेता की जीत कम से कम कुछ समय के लिए हुई थी, इसकी "नकल करने की क्षमता" मानव टाइपिंग त्रुटियां। " [40] ट्यूरिंग ने खुद यह सुझाव दिया था कि कार्यक्रम अपने आउटपुट में त्रुटियों को जोड़ते हैं, ताकि खेल के बेहतर "खिलाड़ी" बन सकें। [64]
- कुछ बुद्धिमान व्यवहार अमानवीय है
- ट्यूरिंग परीक्षण अत्यधिक बुद्धिमान व्यवहारों के लिए परीक्षण नहीं करता है, जैसे कि कठिन समस्याओं को हल करने या मूल अंतर्दृष्टि के साथ आने की क्षमता। वास्तव में, इसे विशेष रूप से मशीन के हिस्से पर धोखे की आवश्यकता होती है: यदि मशीन मनुष्य से अधिक बुद्धिमान है तो उसे जानबूझकर बहुत बुद्धिमान दिखने से बचना चाहिए। यदि यह एक कम्प्यूटेशनल समस्या को हल करना था जो मानव के लिए हल करने के लिए व्यावहारिक रूप से असंभव है, तो पूछताछकर्ता को पता होगा कि कार्यक्रम मानव नहीं है, और मशीन परीक्षण में विफल हो जाएगी।
- क्योंकि यह बुद्धि को माप नहीं सकता है जो मनुष्यों की क्षमता से परे है, परीक्षण का उपयोग उन प्रणालियों के निर्माण या मूल्यांकन के लिए नहीं किया जा सकता है जो मनुष्यों की तुलना में अधिक बुद्धिमान हैं। इस वजह से, कई परीक्षण विकल्प जो सुपर-इंटेलिजेंट सिस्टम का मूल्यांकन करने में सक्षम होंगे, प्रस्तावित किए गए हैं। [65]
चेतना बनाम चेतना का अनुकरण
ट्यूरिंग परीक्षा सख्ती से संबंधित है कि विषय कैसे कार्य करता है - मशीन का बाहरी व्यवहार। इस संबंध में, यह मन के अध्ययन के लिए एक व्यवहारवादी या कार्यात्मकवादी दृष्टिकोण लेता है। एलिज़ा का उदाहरण बताता है कि परीक्षण को पारित करने वाली एक मशीन यांत्रिक नियमों के एक सरल (लेकिन बड़ी) सूची का अनुसरण करके, बिना किसी विचार के या बिना किसी विचार के मानव संवादी व्यवहार का अनुकरण करने में सक्षम हो सकती है।
जॉन सियरल ने तर्क दिया है कि बाहरी व्यवहार का उपयोग यह निर्धारित करने के लिए नहीं किया जा सकता है कि एक मशीन "वास्तव में" सोच है या केवल "सोच का अनुकरण है।" [34] उनकी चीनी कक्ष तर्क है कि दिखाने के लिए करना है, भले ही ट्यूरिंग परीक्षण बुद्धि का एक अच्छा परिचालन परिभाषा है, यह संकेत नहीं हो सकता मशीन एक है कि मन , चेतना , या वैचारिकता । (विचारशीलता कुछ के बारे में "विचारों" की शक्ति के लिए एक दार्शनिक शब्द है। )
Turing anticipated this line of criticism in his original paper,[66] writing:
I do not wish to give the impression that I think there is no mystery about consciousness. There is, for instance, something of a paradox connected with any attempt to localise it. But I do not think these mysteries necessarily need to be solved before we can answer the question with which we are concerned in this paper.[67]
पूछताछकर्ताओं और मानवविषयक पतन की नास्तिकता
व्यवहार में, परीक्षण के परिणामों को आसानी से कंप्यूटर की बुद्धिमत्ता पर नहीं, बल्कि प्रश्नकर्ता के दृष्टिकोण, कौशल या भोलेपन द्वारा हावी किया जा सकता है।
ट्यूरिंग ने परीक्षण के अपने विवरण में पूछताछकर्ता द्वारा आवश्यक सटीक कौशल और ज्ञान को निर्दिष्ट नहीं किया है, लेकिन उन्होंने "औसत पूछताछकर्ता" शब्द का उपयोग किया: "[] औसत पूछताछकर्ता के पास अधिकार बनाने का 70 प्रतिशत से अधिक मौका नहीं होगा। पांच मिनट की पूछताछ के बाद पहचान "। [68]
एलीज़ा जैसे चैटरबॉट कार्यक्रमों ने बार-बार लोगों को यह विश्वास दिलाने में नाकाम बना दिया है कि वे इंसानों के साथ संवाद कर रहे हैं। इन मामलों में, "पूछताछकर्ताओं" को इस संभावना के बारे में भी पता नहीं है कि वे कंप्यूटर के साथ बातचीत कर रहे हैं। मानव को सफलतापूर्वक प्रदर्शित करने के लिए, मशीन को किसी भी तरह की बुद्धि की आवश्यकता नहीं है और केवल मानव व्यवहार के लिए एक सतही समानता की आवश्यकता है।
प्रारंभिक Loebner Prize प्रतियोगिताओं में "बेतरतीब" पूछताछकर्ताओं का उपयोग किया जाता था, जिन्हें आसानी से मशीनों द्वारा मूर्ख बनाया जाता था। [41] 2004 के बाद से, लोएबनेर पुरस्कार आयोजकों ने पूछताछ के बीच दार्शनिकों, कंप्यूटर वैज्ञानिकों और पत्रकारों को तैनात किया है। बहरहाल, इनमें से कुछ विशेषज्ञों ने मशीनों द्वारा धोखा दिया है। [69]
माइकल शरमर बताते हैं कि मानव लगातार गैर-मानव वस्तुओं को मानव के रूप में मानने के लिए चुनते हैं जब भी उन्हें मौका दिया जाता है, एक गलती जिसे एन्थ्रोपोमोर्फिक फॉलिकेसी कहा जाता है : वे अपनी कारों से बात करते हैं, प्राकृतिक शक्तियों के लिए इच्छा और इरादे लिखते हैं (उदाहरण के लिए, "नेचर एब्स) एक वैक्यूम "), और बुद्धि के साथ एक मानव की तरह सूर्य की पूजा करें। यदि ट्यूरिंग परीक्षण धार्मिक वस्तुओं पर लागू होता है, तो शरमेर का तर्क है, कि, निर्जीव मूर्तियों, चट्टानों और स्थानों ने लगातार पूरे इतिहास में परीक्षा उत्तीर्ण की है। एन्थ्रोपोमोर्फिज़्म के प्रति यह मानव प्रवृत्ति ट्यूरिंग परीक्षण के लिए प्रभावी रूप से बार को कम करती है, जब तक कि पूछताछकर्ताओं को विशेष रूप से इससे बचने के लिए प्रशिक्षित नहीं किया जाता है।
मानव की गलत पहचान
ट्यूरिंग टेस्ट की एक दिलचस्प विशेषता कंफ़ेडरेट प्रभाव की आवृत्ति है, जब कंफ़ेडरेट (परीक्षण किए गए) मनुष्यों को पूछताछकर्ताओं द्वारा मशीनों के रूप में गलत समझा जाता है। यह सुझाव दिया गया है कि इंट्रोगेटर्स क्या उम्मीद करते हैं क्योंकि मानव प्रतिक्रियाएं आवश्यक रूप से मनुष्यों की विशिष्ट नहीं हैं। नतीजतन, कुछ व्यक्तियों को मशीनों के रूप में वर्गीकृत किया जा सकता है। इसलिए यह एक प्रतिस्पर्धी मशीन के पक्ष में काम कर सकता है। मनुष्यों को "स्वयं कार्य करने" का निर्देश दिया जाता है, लेकिन कभी-कभी उनके उत्तर अधिक होते हैं जैसे पूछताछकर्ता मशीन को कहने की अपेक्षा करता है। [70] यह इस सवाल को उठाता है कि कैसे सुनिश्चित करें कि मानव "मानव कार्य" करने के लिए प्रेरित हो।
शांति
ट्यूरिंग परीक्षण का एक महत्वपूर्ण पहलू यह है कि एक मशीन को अपने उच्चारण के द्वारा खुद को मशीन के रूप में दूर रखना चाहिए। एक पूछताछकर्ता को तब मशीन को ठीक से पहचान कर "सही पहचान" बनाना चाहिए। हालांकि अगर कोई मशीन बातचीत के दौरान चुप रहती है, यानी पाँचवाँ हिस्सा लेती है , तो एक पूछताछकर्ता के लिए किसी गणना अनुमान के माध्यम से मशीन की सही पहचान करना संभव नहीं है। [71] यहां तक कि परीक्षण के हिस्से के रूप में एक समानांतर / छिपे हुए मानव को ध्यान में रखते हुए स्थिति को मदद नहीं मिल सकती है क्योंकि मशीन के रूप में मनुष्यों को अक्सर गलत तरीके से पहचाना जा सकता है। [72]
अव्यवहारिकता और अप्रासंगिकता: ट्यूरिंग परीक्षण और एआई अनुसंधान
मुख्यधारा के एआई शोधकर्ताओं का तर्क है कि ट्यूरिंग परीक्षण को पारित करने की कोशिश करना अधिक फलदायी शोध से केवल एक व्याकुलता है। [42] दरअसल, ट्यूरिंग परीक्षण नहीं ज्यादा शैक्षणिक या व्यावसायिक प्रयास के रूप में के एक सक्रिय ध्यान केंद्रित है स्टुअर्ट रसेल और पीटर Norvig लिखने: "ऐ शोधकर्ताओं ट्यूरिंग परीक्षण पारित करने के लिए थोड़ा ध्यान समर्पित किया है।" [73] इसके कई कारण हैं।
सबसे पहले, उनके कार्यक्रमों का परीक्षण करने के आसान तरीके हैं। एआई-संबंधित क्षेत्रों में अधिकांश वर्तमान शोध का उद्देश्य मामूली और विशिष्ट लक्ष्यों, जैसे स्वचालित समय-निर्धारण , वस्तु मान्यता , या लॉजिस्टिक्स पर है। इन समस्याओं को हल करने वाले कार्यक्रमों की बुद्धिमत्ता का परीक्षण करने के लिए, एआई शोधकर्ता उन्हें सीधे कार्य देते हैं। रसेल और नॉरविग उड़ान के इतिहास के साथ एक समानता का सुझाव देते हैं: विमानों का परीक्षण किया जाता है कि वे कितनी अच्छी तरह से उड़ते हैं, पक्षियों की तुलना करके नहीं। " एरोनॉटिकल इंजीनियरिंग ग्रंथों," वे लिखते हैं, "के रूप में अपने क्षेत्र के लक्ष्य को परिभाषित करते हैं न की मशीनों कि इतने वास्तव में की तरह उड़ कर रही कबूतरों है कि वे अन्य कबूतरों मूर्ख कर सकते हैं। '" [73]
दूसरा, मनुष्य का जीवनकाल सिमुलेशन बनाना अपने आप में एक कठिन समस्या है जिसे एआई अनुसंधान के मूल लक्ष्यों को प्राप्त करने के लिए हल करने की आवश्यकता नहीं है। विश्वसनीय मानव चरित्र कला, एक खेल , या एक परिष्कृत उपयोगकर्ता इंटरफ़ेस के काम में दिलचस्प हो सकता है , लेकिन वे बुद्धिमान मशीन बनाने के विज्ञान का हिस्सा नहीं हैं, अर्थात्, ऐसी मशीनें जो बुद्धि का उपयोग करके समस्याओं को हल करती हैं।
ट्यूरिंग कृत्रिम बुद्धि के दर्शन की चर्चा में सहायता करने के लिए एक स्पष्ट और समझने योग्य उदाहरण प्रदान करना चाहते थे। [74] जॉन मैकार्थी मानते हैं कि एआई के दर्शन "विज्ञान के अभ्यास पर आमतौर पर विज्ञान के दर्शन की तुलना में एआई अनुसंधान के अभ्यास पर अधिक प्रभाव होने की संभावना नहीं है। [75]
संज्ञानात्मक विज्ञान
रॉबर्ट फ्रेंच (1990) इस मामले को बनाता है कि एक पूछताछकर्ता मानव संज्ञानात्मक विज्ञान द्वारा अध्ययन किए गए निम्न स्तर (यानी, बेहोश) प्रक्रियाओं को प्रकट करने वाले प्रश्नों को प्रस्तुत करके मानव और गैर-मानव वार्ताकारों को अलग कर सकता है। इस तरह के सवाल विचार के मानव अवतार के सटीक विवरणों को प्रकट करते हैं और एक कंप्यूटर को तब तक अनमैक कर सकते हैं जब तक कि यह दुनिया का अनुभव नहीं करता जैसा कि मनुष्य करते हैं। [76]
बदलाव
ट्यूरिंग परीक्षण के कई अन्य संस्करण, जिनमें ऊपर के विस्तार भी शामिल हैं, वर्षों के माध्यम से उठाए गए हैं।
रिवर्स ट्यूरिंग टेस्ट और कैप्चा
ट्यूरिंग परीक्षण का एक संशोधन जिसमें एक या एक से अधिक भूमिकाओं के उद्देश्य को मशीनों और मनुष्यों के बीच उलट दिया गया है और इसे रिवर्स ट्यूरिंग परीक्षण कहा जाता है। एक उदाहरण मनोविश्लेषक विल्फ्रेड बायोन के काम में निहित है, [77] who in [77] जो विशेष रूप से "तूफान" से मोहित हो गया था, जिसके परिणामस्वरूप एक मन का दूसरे द्वारा सामना किया गया था। ट्यूरिंग परीक्षण के संबंध में कई अन्य मूल बिंदुओं के बीच उनकी 2000 की किताब, [55] में, साहित्यिक विद्वान पीटर स्विरस्की ने स्विरस्की परीक्षण को अनिवार्य रूप से रिवर्स ट्यूरिंग परीक्षण कहा था। उन्होंने कहा कि यदि मानक संस्करण पर सभी मानक आपत्तियाँ नहीं लगाई जाती हैं तो यह सबसे अधिक हो जाता है।
इस विचार को आगे बढ़ाते हुए, आरडी हिंसेलवुड [78] ने मन को "मन को पहचानने वाले तंत्र" के रूप में वर्णित किया। कंप्यूटर के लिए यह चुनौती होगी कि वह यह निर्धारित कर सके कि वह मानव या किसी अन्य कंप्यूटर से बातचीत कर रहा है या नहीं। यह मूल प्रश्न का एक विस्तार है जिसे ट्यूरिंग ने उत्तर देने का प्रयास किया है, लेकिन, एक मशीन को परिभाषित करने के लिए एक उच्च पर्याप्त मानक की पेशकश करेगा, जो "सोच" सकता है इस तरह से कि हम आम तौर पर चरित्रवान रूप से मानव के रूप में परिभाषित करते हैं।
कैप्चा रिवर्स ट्यूरिंग टेस्ट का एक रूप है। किसी वेबसाइट पर कुछ कार्रवाई करने की अनुमति देने से पहले, उपयोगकर्ता को विकृत ग्राफिक छवि में अल्फ़ान्यूमेरिकल वर्णों के साथ प्रस्तुत किया जाता है और उन्हें टाइप करने के लिए कहा जाता है। इसका उद्देश्य स्वचालित प्रणालियों को साइट का दुरुपयोग करने से रोकने के लिए किया जाता है। तर्क यह है कि विकृत छवि को पढ़ने और पुन: पेश करने के लिए पर्याप्त रूप से परिष्कृत सॉफ़्टवेयर मौजूद नहीं है (या औसत उपयोगकर्ता के लिए उपलब्ध नहीं है), इसलिए ऐसा करने में सक्षम किसी भी प्रणाली का मानव होना संभव है।
सॉफ्टवेयर जो कैप्चा को उत्पन्न करने के पैटर्न में विश्लेषण करके कुछ सटीकता के साथ कैप्चा को उलट सकता है, कैप्चा के निर्माण के तुरंत बाद विकसित किया जाने लगा। [79] 2013 में, विकरियस के शोधकर्ताओं ने घोषणा की कि उन्होंने Google , Yahoo से कैप्चा चुनौतियों को हल करने के लिए एक प्रणाली विकसित की है ! , और पेपाल 90% समय तक। [80] 2014 में, Google इंजीनियरों ने एक प्रणाली का प्रदर्शन किया जो 99.8% सटीकता के साथ कैप्चा चुनौतियों को हरा सकता था। [81] 2015 में, Google के पूर्व क्लिक धोखाधड़ी czar , Shuman Ghosemajumder , ने कहा कि ऐसी साइबर साइटें थीं जो कैप्चा की चुनौतियों को एक शुल्क के लिए पराजित करेगी, ताकि धोखाधड़ी के विभिन्न रूपों को सक्षम किया जा सके। [82]
विषय विशेषज्ञ विशेषज्ञ ट्यूरिंग टेस्ट
एक अन्य भिन्नता को विषय वस्तु विशेषज्ञ ट्यूरिंग टेस्ट के रूप में वर्णित किया जाता है, जहां एक मशीन की प्रतिक्रिया किसी दिए गए क्षेत्र के विशेषज्ञ से अलग नहीं की जा सकती है। इसे "फ़ेगनबाम टेस्ट" के रूप में भी जाना जाता है और इसे 2003 के एक पेपर में एडवर्ड फेगेनबाम द्वारा प्रस्तावित किया गया था। [83]
कुल ट्यूरिंग टेस्ट
"ट्यूरिंग ट्यूरिंग टेस्ट" [47] ट्यूरिंग टेस्ट की भिन्नता, संज्ञानात्मक वैज्ञानिक स्टवान हरनाड द्वारा प्रस्तावित, [84] पारंपरिक ट्यूरिंग परीक्षण के लिए दो और आवश्यकताओं को जोड़ता है। पूछताछकर्ता विषय की अवधारणात्मक क्षमताओं ( कंप्यूटर विज़न की आवश्यकता) और वस्तुओं को हेरफेर करने के लिए विषय की क्षमता ( रोबोटिक्स की आवश्यकता) का परीक्षण भी कर सकता है। [85]
इलेक्ट्रॉनिक स्वास्थ्य रिकॉर्ड
ACM के संचार में प्रकाशित एक पत्र [86] एक सिंथेटिक रोगी आबादी पैदा करने की अवधारणा का वर्णन करता है और सिंथेटिक और वास्तविक रोगियों के बीच अंतर का आकलन करने के लिए ट्यूरिंग परीक्षण की विविधता का प्रस्ताव करता है। पत्र में कहा गया है: "EHR संदर्भ में, हालांकि एक मानव चिकित्सक आसानी से कृत्रिम रूप से उत्पन्न और वास्तविक जीवित मानव रोगियों के बीच अंतर कर सकता है, क्या एक मशीन को अपने दम पर इस तरह का निर्धारण करने के लिए बुद्धि दी जा सकती है?" और आगे पत्र में कहा गया है: "सिंथेटिक रोगी की पहचान सार्वजनिक स्वास्थ्य समस्या बनने से पहले, वैध ईएचआर बाजार ट्यूरिंग टेस्ट जैसी तकनीकों को लागू करने से अधिक डेटा विश्वसनीयता और नैदानिक मूल्य सुनिश्चित करने के लिए लाभ हो सकता है। इस प्रकार किसी भी नई तकनीक को रोगियों की व्यापकता पर विचार करना चाहिए और एलन आठवीं कक्षा-विज्ञान-परीक्षण की तुलना में अधिक जटिलता होने की संभावना है। "
न्यूनतम बुद्धिमान संकेत परीक्षण
न्यूनतम बुद्धिमान संकेत परीक्षण का प्रस्ताव क्रिस मैककंट्री द्वारा "ट्यूरिंग टेस्ट की अधिकतम अमूर्तता" के रूप में किया गया था, [87] जिसमें केवल द्विआधारी प्रतिक्रियाओं (सही / गलत या हाँ / नहीं) की अनुमति है, केवल विचार की क्षमता पर ध्यान केंद्रित करने के लिए। यह एंथ्रोपोमोर्फिज्म पूर्वाग्रह जैसी पाठ चैट समस्याओं को समाप्त करता है, और मानव बुद्धि से अधिक की व्यवस्था करने की अनुमति देने वाले मानव व्यवहार के अनैतिक रूप से अनुकरण की आवश्यकता नहीं है। प्रश्न प्रत्येक को अपने दम पर खड़े होने चाहिए, हालांकि, यह एक पूछताछ की तुलना में एक आईक्यू परीक्षण की तरह बनाता है। यह आमतौर पर सांख्यिकीय आंकड़ों को इकट्ठा करने के लिए उपयोग किया जाता है, जिसके खिलाफ कृत्रिम बुद्धिमत्ता कार्यक्रमों के प्रदर्शन को मापा जा सकता है। [88]
हटर प्राइज
हटर प्राइज़ के आयोजकों का मानना है कि ट्यूरिंग टेस्ट पास करने के बराबर प्राकृतिक भाषा पाठ को संकुचित करना एक कठिन एआई समस्या है।
डेटा संपीड़न परीक्षण में ट्यूरिंग परीक्षण के अधिकांश संस्करणों और विविधताओं पर कुछ फायदे हैं, जिनमें शामिल हैं:
- यह एक एकल संख्या देता है जिसका उपयोग सीधे दो मशीनों में से किसकी तुलना में किया जा सकता है "अधिक बुद्धिमान।"
- यह कंप्यूटर को न्यायाधीश से झूठ बोलने की आवश्यकता नहीं है
परीक्षण के रूप में डेटा संपीड़न का उपयोग करने के मुख्य नुकसान हैं:
- इस तरह से इंसानों का परीक्षण करना संभव नहीं है।
- यह अज्ञात है कि इस परीक्षण पर विशेष रूप से "स्कोर" क्या है - यदि कोई भी मानव-स्तरीय ट्यूरिंग टेस्ट पास करने के बराबर है।
संपीड़न या कोलमोगोरोव जटिलता के आधार पर अन्य परीक्षण
हूटर के पुरस्कार से संबंधित एक दृष्टिकोण जो 1990 के दशक के उत्तरार्ध में बहुत पहले दिखाई दिया था, एक विस्तारित ट्यूरिंग परीक्षण में संपीड़न समस्याओं का समावेश है। [89] या परीक्षणों द्वारा जो पूरी तरह से कोलमोगोरोव जटिलता से प्राप्त होते हैं। [90] इस पंक्ति में अन्य संबंधित परीक्षण हर्नान्डेज़-ओरलो और डोवे द्वारा प्रस्तुत किए गए हैं। [91]
अल्गोरिथमिक आईक्यू या शॉर्ट के लिए एआईक्यू, लेग और हटर से सैद्धांतिक यूनिवर्सल इंटेलिजेंस उपाय ( सोलोमनॉफ के प्रेरक निष्कर्ष पर आधारित) को मशीन इंटेलिजेंस के एक व्यावहारिक व्यावहारिक परीक्षण में बदलने का प्रयास है। [92]
इनमें से कुछ परीक्षणों के दो प्रमुख लाभ हैं, गैर-मानवीय बुद्धिमता के लिए उनकी प्रयोज्यता और मानव परीक्षकों के लिए उनकी अनुपस्थिति।
एबर्ट परीक्षण
ट्यूरिंग परीक्षण ने 2011 में फिल्म समीक्षक रोजर एबर्ट द्वारा प्रस्तावित एबर्ट परीक्षण को प्रेरित किया, जो एक परीक्षण है कि क्या कंप्यूटर-आधारित संश्लेषित आवाज में लोगों को हँसाने के लिए इंटोनेशन, विभक्ति, समय और इसके आगे के रूप में पर्याप्त कौशल है। [93]
भविष्यवाणियों
ट्यूरिंग ने भविष्यवाणी की कि मशीनें अंततः परीक्षण पास करने में सक्षम होंगी; वास्तव में, उन्होंने अनुमान लगाया कि वर्ष 2000 तक, लगभग 100 एमबी स्टोरेज वाली मशीनें पांच मिनट की परीक्षा में 30% मानव न्यायाधीशों को बेवकूफ बनाने में सक्षम होंगी, और लोग अब "सोच मशीन" के विरोधाभासी वाक्यांश पर विचार नहीं करेंगे। [4] (व्यवहार में, 2009-2012 से, Loebner पुरस्कार chatterbot प्रतियोगियों केवल एक बार एक जज को बेवकूफ बनाने, प्रबंधित [94] और कहा कि केवल करने के लिए मानव प्रतियोगी एक होने का नाटक कारण chatbot [95] उन्होंने आगे भविष्यवाणी) यह मशीन सीखना शक्तिशाली मशीनों के निर्माण का एक महत्वपूर्ण हिस्सा होगा, एक दावा जिसे कृत्रिम बुद्धिमत्ता में समकालीन शोधकर्ताओं द्वारा प्रशंसनीय माना जाता है। [68]
19 वें मिडवेस्ट आर्टिफिशियल इंटेलिजेंस एंड कॉग्निटिव साइंस कॉन्फ्रेंस को सौंपे गए 2008 के एक पेपर में, डॉ। शेन टी। मुलर ने एक संशोधित ट्यूरिंग टेस्ट की भविष्यवाणी की जिसे "कॉग्निटिव डेकाथलॉन" कहा जाता है, जिसे पांच साल के भीतर पूरा किया जा सकता है। [96]
कई दशकों में प्रौद्योगिकी के एक घातीय विकास को अतिरिक्त करके, भविष्यवादी रे कुर्ज़वील ने भविष्यवाणी की कि निकट भविष्य में ट्यूरिंग टेस्ट-सक्षम कंप्यूटर निर्मित होंगे। 1990 में, उन्होंने वर्ष 2020 के आसपास सेट किया। [97] 2005 तक, उन्होंने अपने अनुमान को 2029 तक संशोधित किया। [98]
लॉन्ग बेट प्रोजेक्ट बेट एनआर। 1 मिच कपूर (निराशावादी) और रे कुर्ज़वील (आशावादी) के बीच $ 20,000 का दांव है कि क्या वर्ष 2029 तक एक कंप्यूटर एक लंबा ट्यूरिंग टेस्ट पास करेगा। लॉन्ग नाउ ट्यूरिंग टेस्ट के दौरान, तीन ट्यूरिंग टेस्ट जजों में से प्रत्येक चार ट्यूरिंग टेस्ट उम्मीदवारों (यानी, कंप्यूटर और तीन ट्यूरिंग टेस्ट मानव foils) में से प्रत्येक के ऑनलाइन साक्षात्कार का आयोजन करेगा, कुल आठ घंटे के साक्षात्कार के लिए दो घंटे। । शर्त कुछ विवरण में शर्तों को निर्दिष्ट करती है। [99]
सम्मेलन
ट्यूरिंग बोलचाल
1990 ने ट्यूरिंग के "कम्प्यूटिंग मशीनरी एंड इंटेलिजेंस" पेपर के पहले प्रकाशन की चालीसवीं वर्षगांठ को चिह्नित किया, और परीक्षण में नए सिरे से रुचि दिखाई। उस वर्ष में दो महत्वपूर्ण घटनाएं हुईं: पहला ट्यूरिंग कोलॉक्विम था, जो अप्रैल में ससेक्स विश्वविद्यालय में आयोजित किया गया था, और अपने अतीत, वर्तमान के संदर्भ में ट्यूरिंग टेस्ट पर चर्चा करने के लिए कई प्रकार के विषयों के शिक्षाविदों और शोधकर्ताओं को साथ लाया , और भविष्य; दूसरा वार्षिक Loebner Prize प्रतियोगिता का गठन था।
ब्लय व्हिटबी ने ट्यूरिंग टेस्ट के इतिहास में चार प्रमुख मोड़ दिए - 1950 में "कम्प्यूटिंग मशीनरी और खुफिया" का प्रकाशन की घोषणा जोसेफ वाइज़ेनबम के ELIZA 1966 में, केनेथ कोल्बी के के निर्माण पैरी , जो पहली बार 1972 में वर्णित किया गया था, और 1990 में ट्यूरिंग वार्तालाप [100]
2005 बोलचाल की व्यवस्था पर बोलचाल
नवंबर 2005 में, सरे विश्वविद्यालय ने कृत्रिम संवादी इकाई विकासकर्ताओं की एक दिवसीय बैठक की मेजबानी की, [101] जिसमें लोबेनर पुरस्कार में व्यावहारिक ट्यूरिंग परीक्षणों के विजेताओं ने भाग लिया: रॉबी गार्नर , रिचर्ड वालेस और रोलर्स बढ़ई आमंत्रित वक्ताओं में डेविड हेमिल, ह्यूग लोएबनेर ( लोएबनेर पुरस्कार के प्रायोजक) और हुमा शाह शामिल थे ।
2008 AISB संगोष्ठी
रीडिंग विश्वविद्यालय में आयोजित 2008 के Loebner Prize के समानांतर, [102] आर्टिफिशियल इंटेलिजेंस के अध्ययन के लिए सोसायटी और व्यवहार (AISB) के सिमुलेशन , जॉन बैरडेन द्वारा आयोजित टैस्ट टेस्ट पर चर्चा करने के लिए एक दिवसीय संगोष्ठी की मेजबानी की , मार्क बिशप , हुमा शाह और केविन वारविक । [103] वक्ताओं में रॉयल इंस्टीट्यूशन के निदेशक बैरोनेस सुसान ग्रीनफील्ड , सेल्मर ब्रिंग्सजॉर्ड , ट्यूरिंग के जीवनी लेखक एंड्रयू होजेस और चेतना वैज्ञानिक ओवेन हॉलैंड शामिल थे । कैनिंगिकल ट्यूरिंग टेस्ट के लिए कोई समझौता नहीं हुआ, हालांकि ब्रिंगजॉर्ड ने व्यक्त किया कि एक बड़ा पुरस्कार ट्यूरिंग टेस्ट में जल्द ही पास हो जाएगा।
2012 में एलन ट्यूरिंग ईयर, और ट्यूरिंग 100
पूरे 2012 में, ट्यूरिंग के जीवन और वैज्ञानिक प्रभाव को मनाने के लिए कई प्रमुख कार्यक्रम हुए। ट्यूरिंग 100 समूह ने इन घटनाओं का समर्थन किया और इसके अलावा, 23 जून 2012 को बैलेचले पार्क में ट्यूरिंग के जन्म की 100 वीं वर्षगांठ मनाने के लिए एक विशेष ट्यूरिंग परीक्षण कार्यक्रम का आयोजन किया।
संदर्भ
- ↑ छवि 2000, Saygin से अनुकूलित।
- ↑ Turing originally suggested a teleprinter, one of the few text-only communication systems available in 1950. (Turing 1950, p. 433)
- ↑ "The Turing Test, 1950". turing.org.uk. The Alan Turing Internet Scrapbook. मूल से 3 अप्रैल 2019 को पुरालेखित. अभिगमन तिथि 23 मार्च 2019.
- ↑ अ आ इ ई Turing 1950, पृ॰ 433.
- ↑ (Turing 1950, p. 442) Turing does not call his idea "Turing test", but rather the "Imitation Game"; however, later literature has reserved the term "Imitation game" to describe a particular version of the test. See #Versions of the Turing test, below. Turing gives a more precise version of the question later in the paper: "[T]hese questions [are] equivalent to this, 'Let us fix our attention on one particular digital computer C. Is it true that by modifying this computer to have an adequate storage, suitably increasing its speed of action, and providing it with an appropriate programme, C can be made to play satisfactorily the part of A in the imitation game, the part of B being taken by a man?साँचा:' " (Turing 1950, p. 442)
- ↑ अ आ Turing 1950 and see Russell & Norvig (2003, p. 948), where they comment, "Turing examined a wide variety of possible objections to the possibility of intelligent machines, including virtually all of those that have been raised in the half century since his paper appeared." सन्दर्भ त्रुटि:
<ref>अमान्य टैग है; "Turing's nine objections" नाम कई बार विभिन्न सामग्रियों में परिभाषित हो चुका है - ↑ अ आ इ ई उ ऊ Saygin 2000.
- ↑ Russell & Norvig 2003, पृ॰प॰ 2–3 and 948.
- ↑ Descartes, René (1996). Discourse on Method and Meditations on First Philosophy. New Haven & London: Yale University Press. पपृ॰ 34–5. आई॰ऍस॰बी॰ऍन॰ 978-0300067729.
- ↑ Diderot, D. (2007), Pensees Philosophiques, Addition aux Pensees Philosophiques, [Flammarion], पृ॰ 68, आई॰ऍस॰बी॰ऍन॰ 978-2-0807-1249-3
- ↑ गुण द्वैतवाद के उदाहरण के लिए, क्वालिया देखें।
- ↑ यह देखते हुए कि भौतिकवाद कृत्रिम दिमाग की संभावना की जरूरत नहीं है (उदाहरण के लिए, रोजर पेनरोस ), द्वैतवाद से किसी भी अधिक जरूरी संभावना निवारण होता है। (देखें, उदाहरण के लिए, संपत्ति द्वैतवाद ।)
- ↑ Ayer, A. J. (2001), "Language, Truth and Logic", Nature, Penguin, 138 (3498), पृ॰ 140, आई॰ऍस॰बी॰ऍन॰ 978-0-334-04122-1, डीओआइ:10.1038/138823a0, बिबकोड:1936Natur.138..823G
- ↑ The Dartmouth conferences of 1956 are widely considered the "birth of AI". (Crevier 1993, p. 49)
- ↑ McCorduck 2004, पृ॰ 95.
- ↑ Copeland 2003, पृ॰ 1.
- ↑ Copeland 2003, पृ॰ 2.
- ↑ "इंटेलिजेंट मशीनरी" (1948) ट्यूरिंग द्वारा प्रकाशित नहीं किया गया था, और इसमें 1968 तक प्रकाशन नहीं देखा गया था:
- ↑ Turing 1948, पृ॰ 412.
- ↑ Turing 1948, पृ॰ [].
- ↑ Harnad 2004, पृ॰ 1.
- ↑ अ आ इ ई उ Turing 1950, पृ॰ 434.
- ↑ अ आ Shah 2010.
- ↑ Turing 1950, पृ॰ 446.
- ↑ Turing 1952. Turing does not seem to distinguish between "man" as a gender and "man" as a human. In the former case, this formulation would be closer to the imitation game, whereas in the latter it would be closer to current depictions of the test.
- ↑ Weizenbaum 1966, पृ॰ 37.
- ↑ अ आ इ ई उ Weizenbaum 1966, पृ॰ 42.
- ↑ Thomas 1995, पृ॰ 112.
- ↑ Bowden 2006, पृ॰ 370.
- ↑ Colby et al. 1972, पृ॰ 42.
- ↑ Saygin 2000, पृ॰ 501.
- ↑ Withers, Steven (11 December 2007), "Flirty Bot Passes for Human", iTWire, मूल से 4 अक्तूबर 2017 को पुरालेखित, अभिगमन तिथि 23 मार्च 2019
- ↑ Williams, Ian (10 December 2007), "Online Love Seerkers Warned Flirt Bots", V3, मूल से 24 अप्रैल 2010 को पुरालेखित, अभिगमन तिथि 23 मार्च 2019
- ↑ अ आ Searle 1980.
- ↑ सेरेल के चीनी कमरे के खिलाफ बड़ी संख्या में तर्क हैं । कुछ हैं:
- ↑ एम। बिशप और जे। प्रेस्टन (सं।) (2001) सेरेले के चीनी कक्ष तर्क पर निबंध। ऑक्सफोर्ड यूनिवरसिटि प्रेस।
- ↑ Saygin 2000, पृ॰ 479.
- ↑ Sundman 2003.
- ↑ Loebner 1994.
- ↑ अ आ इ "Artificial Stupidity" 1992.
- ↑ अ आ इ Shapiro 1992 and Shieber 1994, amongst others.
- ↑ अ आ Shieber 1994, पृ॰ 77.
- ↑ साँचा:Scientific American Frontiers
- ↑ अ आ इ Traiger 2000.
- ↑ Saygin 2008.
- ↑ अ आ Shah 2011.
- ↑ अ आ ओप्पी, ग्राहम एंड डाउ, डेविड (2011) द ट्यूरिंग टेस्ट Archived 2012-03-20 at the वेबैक मशीन । स्टैनफोर्ड एनसाइक्लोपीडिया ऑफ फिलॉसफी ।
- ↑ अ आ Moor 2003.
- ↑ Traiger 2000, पृ॰ 99.
- ↑ Sterrett 2000.
- ↑ Genova 1994, Hayes & Ford 1995, Heil 1998, Dreyfus 1979
- ↑ R.Epstein, G. Roberts, G. Poland, (eds।) ट्यूरिंग टेस्ट: द थिंकिंग कंप्यूटर के लिए क्वेस्ट में दार्शनिक और पद्धति संबंधी मुद्दे स्प्रिंगर: डॉर्ड्रेक्ट, नीदरलैंड
- ↑ Thompson, Clive (July 2005). "The Other Turing Test". Issue 13.07. WIRED magazine. मूल से 19 अगस्त 2011 को पुरालेखित. अभिगमन तिथि 10 September 2011.
As a gay man who spent nearly his whole life in the closet, Turing must have been keenly aware of the social difficulty of constantly faking your real identity. And there's a delicious irony in the fact that decades of AI scientists have chosen to ignore Turing's gender-twisting test – only to have it seized upon by three college-age women
. (Full version Archived 2019-03-23 at the वेबैक मशीन). - ↑ Colby et al. 1972.
- ↑ अ आ Swirski 2000.
- ↑ Saygin & Cicekli 2002.
- ↑ अ आ Turing 1950, under "Critique of the New Problem".
- ↑ Haugeland 1985, पृ॰ 8.
- ↑ "These six disciplines," write Stuart J. Russell and Peter Norvig, "represent most of AI." Russell & Norvig 2003, पृष्ठ 3
- ↑ वाटसन :
- ↑ Urban, Tim (February 2015). "The AI Revolution: Our Immortality or Extinction". Wait But Why. मूल से 23 मार्च 2019 को पुरालेखित. अभिगमन तिथि April 5, 2015.
- ↑ Smith, G. W. (March 27, 2015). "Art and Artificial Intelligence". ArtEnt. मूल से 25 June 2017 को पुरालेखित. अभिगमन तिथि March 27, 2015. नामालूम प्राचल
|dead-url=की उपेक्षा की गयी (मदद) - ↑ Saygin & Cicekli 2002, पृ॰प॰ 227–258.
- ↑ Turing 1950, पृ॰ 448.
- ↑ ट्यूरिंग परीक्षण के कई विकल्प, जो मनुष्यों की तुलना में अधिक बुद्धिमान मशीनों का मूल्यांकन करने के लिए डिज़ाइन किए गए हैं:
- ↑ Russell & Norvig (2003, pp. 958–960) identify Searle's argument with the one Turing answers.
- ↑ Turing 1950.
- ↑ अ आ Turing 1950, पृ॰ 442.
- ↑ Shah & Warwick 2010.
- ↑ Kevin Warwick; Huma Shah (Jun 2014). "Human Misidentification in Turing Tests". Journal of Experimental and Theoretical Artificial Intelligence. 27 (2): 123–135. डीओआइ:10.1080/0952813X.2014.921734.
- ↑ वारविक, के। और शाह, एच।, "ट्यूरिंग इमीशन गेम में पांचवां संशोधन लेते हुए", जर्नल ऑफ़ एक्सपेरिमेंटल एंड थियोरेटिकल आर्टिफिशियल इंटेलिजेंस , डीओआई: 10.1080 / 0952813X5.11.1132273, 2016
- ↑ वारविक, के। और शाह, एच।, "ट्यूरिंग टेस्ट में मानव गलत पहचान", जर्नल ऑफ़ एक्सपेरिमेंटल एंड थियोरेटिकल आर्टिफिशियल इंटेलिजेंस , वॉल्यूम। 27, अंक 2, पीपी। 123–135, डीओआई: 10.1080 / 0952813X.2014.921734, 2015
- ↑ अ आ Russell & Norvig 2003, पृ॰ 3.
- ↑ Turing 1950, under the heading "The Imitation Game," where he writes, "Instead of attempting such a definition I shall replace the question by another, which is closely related to it and is expressed in relatively unambiguous words."
- ↑ McCarthy, John (1996), "The Philosophy of Artificial Intelligence", What has AI in Common with Philosophy?, मूल से 5 अप्रैल 2019 को पुरालेखित, अभिगमन तिथि 23 मार्च 2019
- ↑ French, Robert M., "Subcognition and the Limits of the Turing Test", Mind, 99 (393), पपृ॰ 53–65
- ↑ अ आ Bion 1979.
- ↑ Hinshelwood 2001.
- ↑ Malik, Jitendra; Mori, Greg, Breaking a Visual CAPTCHA, मूल से 23 मार्च 2019 को पुरालेखित, अभिगमन तिथि 23 मार्च 2019
- ↑ Pachal, Pete, Captcha FAIL: Researchers Crack the Web's Most Popular Turing Test, मूल से 3 दिसंबर 2018 को पुरालेखित, अभिगमन तिथि 23 मार्च 2019
- ↑ Tung, Liam, Google algorithm busts CAPTCHA with 99.8 percent accuracy, मूल से 23 मार्च 2019 को पुरालेखित, अभिगमन तिथि 23 मार्च 2019
- ↑ Ghosemajumder, Shuman, The Imitation Game: The New Frontline of Security, मूल से 23 मार्च 2019 को पुरालेखित, अभिगमन तिथि 23 मार्च 2019
- ↑ McCorduck 2004, Feigenbaum 2003. The subject matter expert test is also mentioned in Kurzweil (2005)
- ↑ Gent, Edd (2014), The Turing Test: brain-inspired computing's multiple-path approach, मूल से 23 मार्च 2019 को पुरालेखित, अभिगमन तिथि 23 मार्च 2019
- ↑ Russell & Norvig 2010, पृ॰ 3.
- ↑ Cacm Staff (2017). "A leap from artificial to intelligence". Communications of the ACM. 61: 10–11. डीओआइ:10.1145/3168260. मूल से 19 नवंबर 2018 को पुरालेखित. अभिगमन तिथि 23 मार्च 2019.
- ↑ "संग्रहीत प्रति". मूल से 30 जून 2013 को पुरालेखित. अभिगमन तिथि 23 मार्च 2019.
- ↑ McKinstry, Chris (1997), "Minimum Intelligent Signal Test: An Alternative Turing Test", Canadian Artificial Intelligence (41), मूल से 31 मार्च 2019 को पुरालेखित, अभिगमन तिथि 23 मार्च 2019
- ↑ D L Dowe & A R Hajek (1997), "A computational extension to the Turing Test", Proceedings of the 4th Conference of the Australasian Cognitive Science Society, मूल से 28 जून 2011 को पुरालेखित, अभिगमन तिथि 21 जुलाई 2009.
- ↑ Jose Hernandez-Orallo (2000), "Beyond the Turing Test", Journal of Logic, Language and Information, 9 (4), पपृ॰ 447–466, CiteSeerX 10.1.1.44.8943, डीओआइ:10.1023/A:1008367325700.
- ↑ Hernandez-Orallo & Dowe 2010.
- ↑ यूनिवर्सल इंटेलिजेंस मीम, शेन लेग और जोएल वेनेसा, 2011 सोलोमनॉफ मेमोरियल कॉन्फ्रेंस का अनाउंसमेंट
- ↑ Alex_Pasternack (18 April 2011). "A MacBook May Have Given Roger Ebert His Voice, But An iPod Saved His Life (Video)". Motherboard. मूल से 6 September 2011 को पुरालेखित. अभिगमन तिथि 12 September 2011.
He calls it the "Ebert Test," after Turing's AI standard...
Italic or bold markup not allowed in:|publisher=(मदद) - ↑ "संग्रहीत प्रति". मूल से 30 दिसंबर 2010 को पुरालेखित. अभिगमन तिथि 23 मार्च 2019.
- ↑ "Prizewinning chatbot steers the conversation". मूल से 17 अप्रैल 2015 को पुरालेखित. अभिगमन तिथि 23 मार्च 2019.
- ↑ Shane T. Mueller (2008), "Is the Turing Test Still Relevant? A Plan for Developing the Cognitive Decathlon to Test Intelligent Embodied Behavior" (PDF), Paper Submitted to the 19th Midwest Artificial Intelligence and Cognitive Science Conference, पपृ॰ 8pp, मूल (PDF) से 5 नवम्बर 2010 को पुरालेखित, अभिगमन तिथि 8 सितम्बर 2010
- ↑ Kurzweil 1990.
- ↑ Kurzweil 2005.
- ↑ Kapor, Mitchell; Kurzweil, Ray, "By 2029 no computer – or "machine intelligence" – will have passed the Turing Test", The Arena for Accountable Predictions: A Long Bet, मूल से 28 मार्च 2019 को पुरालेखित, अभिगमन तिथि 23 मार्च 2019
- ↑ Whitby 1996, पृ॰ 53.
- ↑ ALICE Anniversary and Colloquium on Conversation, A.L.I.C.E. Artificial Intelligence Foundation, मूल से 16 अप्रैल 2009 को पुरालेखित, अभिगमन तिथि 29 March 2009
- ↑ Loebner Prize 2008, University of Reading, अभिगमन तिथि 29 March 2009[मृत कड़ियाँ]
- ↑ AISB 2008 Symposium on the Turing Test, Society for the Study of Artificial Intelligence and the Simulation of Behaviour, मूल से 18 मार्च 2009 को पुरालेखित, अभिगमन तिथि 29 मार्च 2009
आगे की पढाई
- "Artificial Stupidity", The Economist, 324 (7770): 14, 1 August 1992
- Bion, W.S. (1979), "Making the best of a bad job", Clinical Seminars and Four Papers, Abingdon: Fleetwood Press.
- Bowden, Margaret A. (2006), Mind As Machine: A History of Cognitive Science, ऑक्सफोर्ड यूनिवर्सिटी प्रेस, आई॰ऍस॰बी॰ऍन॰ 978-0-19-924144-6
- Colby, K. M.; Hilf, F. D.; Weber, S.; Kraemer, H. (1972), "Turing-like indistinguishability tests for the validation of a computer simulation of paranoid processes", Artificial Intelligence, 3: 199–221, डीओआइ:10.1016/0004-3702(72)90049-5
- Copeland, Jack (2003), Moor, James (संपा॰), "The Turing Test", The Turing Test: The Elusive Standard of Artificial Intelligence, Springer, आई॰ऍस॰बी॰ऍन॰ 978-1-4020-1205-1
- Crevier, Daniel (1993), AI: The Tumultuous Search for Artificial Intelligence, New York, NY: BasicBooks, आई॰ऍस॰बी॰ऍन॰ 978-0-465-02997-6
- Dreyfus, Hubert (1979), What Computers Still Can't Do, New York: MIT Press, आई॰ऍस॰बी॰ऍन॰ 978-0-06-090613-9
- Feigenbaum, Edward A. (2003), "Some challenges and grand challenges for computational intelligence", Journal of the ACM, 50 (1): 32–40, डीओआइ:10.1145/602382.602400
- French, Robert M. (1990), "Subcognition and the Limits of the Turing Test", Mind, 99 (393): 53–65, डीओआइ:10.1093/mind/xcix.393.53
- Genova, J. (1994), "Turing's Sexual Guessing Game", Social Epistemology, 8 (4): 314–326, डीओआइ:10.1080/02691729408578758
- Harnad, Stevan (2004), "The Annotation Game: On Turing (1950) on Computing, Machinery, and Intelligence", प्रकाशित Epstein, Robert; Peters, Grace (संपा॰), The Turing Test Sourcebook: Philosophical and Methodological Issues in the Quest for the Thinking Computer, Klewer, मूल से 6 जुलाई 2011 को पुरालेखित, अभिगमन तिथि 23 मार्च 2019
- Haugeland, John (1985), Artificial Intelligence: The Very Idea, Cambridge, Massachusetts: MIT Press.
- Hayes, Patrick; Ford, Kenneth (1995), "Turing Test Considered Harmful", Proceedings of the Fourteenth International Joint Conference on Artificial Intelligence (IJCAI95-1), Montreal, Quebec, Canada.: 972–997
- Heil, John (1998), Philosophy of Mind: A Contemporary Introduction, London and New York: Routledge, आई॰ऍस॰बी॰ऍन॰ 978-0-415-13060-8
- Hinshelwood, R.D. (2001), Group Mentality and Having a Mind: Reflections on Bion's work on groups and on psychosis
- Kurzweil, Ray (1990), The Age of Intelligent Machines, Cambridge, Massachusetts: MIT Press, आई॰ऍस॰बी॰ऍन॰ 978-0-262-61079-7
- Kurzweil, Ray (2005), The Singularity is Near, Penguin Books, आई॰ऍस॰बी॰ऍन॰ 978-0-670-03384-3, मूल से 9 मार्च 2013 को पुरालेखित, अभिगमन तिथि 23 अक्तूबर 2019
- Loebner, Hugh Gene (1994), "In response", Communications of the ACM, 37 (6): 79–82, डीओआइ:10.1145/175208.175218, मूल से 14 मार्च 2008 को पुरालेखित, अभिगमन तिथि 22 March 2008
- साँचा:McCorduck 2004
- Moor, James, संपा॰ (2003), The Turing Test: The Elusive Standard of Artificial Intelligence, Dordrecht: Kluwer Academic Publishers, आई॰ऍस॰बी॰ऍन॰ 978-1-4020-1205-1
- Penrose, Roger (1989), The Emperor's New Mind: Concerning Computers, Minds, and The Laws of Physics, Oxford University Press, आई॰ऍस॰बी॰ऍन॰ 978-0-14-014534-2
- साँचा:Cite AIMA
- Russell, Stuart J.; Norvig, Peter (2010), Artificial Intelligence: A Modern Approach (3rd संस्करण), Upper Saddle River, NJ: Prentice Hall, आई॰ऍस॰बी॰ऍन॰ 978-0-13-604259-4
- Saygin, A. P.; Cicekli, I.; Akman, V. (2000), "Turing Test: 50 Years Later" (PDF), Minds and Machines, 10 (4): 463–518, hdl:11693/24987, डीओआइ:10.1023/A:1011288000451, मूल (PDF) से 9 अप्रैल 2011 को पुरालेखित, अभिगमन तिथि 23 मार्च 2019. Reprinted in Moor (2003, pp. 23–78).
- Saygin, A. P.; Cicekli, I. (2002), "Pragmatics in human-computer conversation", Journal of Pragmatics, 34 (3): 227–258, CiteSeerX 10.1.1.12.7834, डीओआइ:10.1016/S0378-2166(02)80001-7.
- Saygin, A.P.; Roberts, Gary; Beber, Grace (2008), "Comments on "Computing Machinery and Intelligence" by Alan Turing", प्रकाशित Epstein, R.; Roberts, G.; Poland, G. (संपा॰), Parsing the Turing Test: Philosophical and Methodological Issues in the Quest for the Thinking Computer, Dordrecht, Netherlands: Springer, आई॰ऍस॰बी॰ऍन॰ 978-1-4020-9624-2, डीओआइ:10.1007/978-1-4020-6710-5, बिबकोड:2009pttt.book.....E
- Searle, John (1980), "Minds, Brains and Programs", Behavioral and Brain Sciences, 3 (3): 417–457, डीओआइ:10.1017/S0140525X00005756, मूल से 23 अगस्त 2000 को पुरालेखित, अभिगमन तिथि 23 मार्च 2019. Page numbers above refer to a standard pdf print of the article. See also Searle's original draft.
- Shah, Huma; Warwick, Kevin (2009a), "Emotion in the Turing Test: A Downward Trend for Machines in Recent Loebner Prizes", प्रकाशित Vallverdú, Jordi; Casacuberta, David (संपा॰), Handbook of Research on Synthetic Emotions and Sociable Robotics: New Applications in Affective Computing and Artificial Intelligence, Information Science, IGI, आई॰ऍस॰बी॰ऍन॰ 978-1-60566-354-8
- Shah, Huma; Warwick, Kevin (June 2010), "Hidden Interlocutor Misidentification in Practical Turing Tests", Minds and Machines, 20 (3): 441–454, डीओआइ:10.1007/s11023-010-9219-6
- Shah, Huma; Warwick, Kevin (April 2010), "Testing Turing's Five Minutes Parallel-paired Imitation Game", Kybernetes Turing Test Special Issue, 4 (3): 449, डीओआइ:10.1108/03684921011036178, मूल से 26 सितंबर 2012 को पुरालेखित, अभिगमन तिथि 23 मार्च 2019
- Shapiro, Stuart C. (1992), "The Turing Test and the economist", ACM SIGART Bulletin, 3 (4): 10–11, डीओआइ:10.1145/141420.141423
- Shieber, Stuart M. (1994), "Lessons from a Restricted Turing Test", Communications of the ACM, 37 (6): 70–78, arXiv:cmp-lg/9404002, CiteSeerX 10.1.1.54.3277, डीओआइ:10.1145/175208.175217, मूल से 17 मार्च 2008 को पुरालेखित, अभिगमन तिथि 25 March 2008
- Sterrett, S. G. (2000), "Turing's Two Test of Intelligence", Minds and Machines, 10 (4): 541, hdl:10057/10701, डीओआइ:10.1023/A:1011242120015 (reprinted in The Turing Test: The Elusive Standard of Artificial Intelligence edited by James H. Moor, Kluwer Academic 2003) ISBN 1-4020-1205-5
- Sundman, John (26 फ़रवरी 2003), "Artificial stupidity", Salon.com, मूल से 7 मार्च 2008 को पुरालेखित, अभिगमन तिथि 22 मार्च 2008
- Thomas, Peter J. (1995), The Social and Interactional Dimensions of Human-Computer Interfaces, Cambridge University Press, आई॰ऍस॰बी॰ऍन॰ 978-0-521-45302-8
- Swirski, Peter (2000), Between Literature and Science: Poe, Lem, and Explorations in Aesthetics, Cognitive Science, and Literary Knowledge, McGill-Queen's University Press, आई॰ऍस॰बी॰ऍन॰ 978-0-7735-2078-3
- Traiger, Saul (2000), "Making the Right Identification in the Turing Test", Minds and Machines, 10 (4): 561, डीओआइ:10.1023/A:1011254505902 (reprinted in The Turing Test: The Elusive Standard of Artificial Intelligence edited by James H. Moor, Kluwer Academic 2003) ISBN 1-4020-1205-5
- Turing, Alan (1948), "Machine Intelligence", प्रकाशित Copeland, B. Jack (संपा॰), The Essential Turing: The ideas that gave birth to the computer age, Oxford: Oxford University Press, आई॰ऍस॰बी॰ऍन॰ 978-0-19-825080-7
- साँचा:Turing 1950
- Turing, Alan (1952), "Can Automatic Calculating Machines be Said to Think?", प्रकाशित Copeland, B. Jack (संपा॰), The Essential Turing: The ideas that gave birth to the computer age, Oxford: Oxford University Press, आई॰ऍस॰बी॰ऍन॰ 978-0-19-825080-7
- Zylberberg, A.; Calot, E. (2007), "Optimizing Lies in State Oriented Domains based on Genetic Algorithms", Proceedings VI Ibero-American Symposium on Software Engineering: 11–18, आई॰ऍस॰बी॰ऍन॰ 978-9972-2885-1-7
- Weizenbaum, Joseph (January 1966), "ELIZA – A Computer Program For the Study of Natural Language Communication Between Man And Machine", Communications of the ACM, 9 (1): 36–45, डीओआइ:10.1145/365153.365168
- Whitby, Blay (1996), "The Turing Test: AI's Biggest Blind Alley?", प्रकाशित Millican, Peter; Clark, Andy (संपा॰), Machines and Thought: The Legacy of Alan Turing, 1, ऑक्सफोर्ड यूनिवर्सिटी प्रेस, पपृ॰ 53–62, आई॰ऍस॰बी॰ऍन॰ 978-0-19-823876-8
बाहरी कड़ियाँ
- ट्यूरिंग टेस्ट - जूलियन वागस्टाफ द्वारा एक ओपेरा
- मुक्त निर्देशिका परियोजना पर ट्यूरिंग टेस्ट
- ट्यूरिंग टेस्ट - ट्यूरिंग टेस्ट वास्तव में कितना सही हो सकता है?
- ज़ाल्टा, एडवर्ड एन (सं।)। "द ट्यूरिंग टेस्ट" । स्टैनफोर्ड एनसाइक्लोपीडिया ऑफ फिलॉसफी ।
- ट्यूरिंग टेस्ट: 50 साल बाद 2000 के सहूलियत बिंदु से, ट्यूरिंग टेस्ट पर काम की अर्धशतकीय समीक्षा की।
- कपूर और कुर्ज़वील के बीच शर्त , उनके संबंधित पदों के विस्तृत औचित्य सहित।
- Why Turing Test, Blay Witby द्वारा AI का सबसे बड़ा ब्लाइंड गली है
- Jabberwacky.com एक ऐ chatterbot कि से सीखता है और मनुष्य का अनुकरण
- न्यूयॉर्क टाइम्स मशीन खुफिया भाग 1 और भाग 2 पर निबंध
- " " सीज़न 2, एपिसोड 5 पर "पहला (प्रतिबंधित) ट्यूरिंग टेस्ट" । वैज्ञानिक अमेरिकी फ्रंटियर्स । चेड्ड-एंगियर प्रोडक्शन कंपनी। 1991-1992। पीबीएस । 2006 को मूल से संग्रहित ।
- कंप्यूटर विज्ञान ने ट्यूरिंग टेस्ट के लिए अनप्लग्ड शिक्षण गतिविधि ।
- विकी न्यूज़: "टॉक: कंप्यूटर पेशेवर एलिस का 10 वां जन्मदिन मनाते हैं"